














Знакомое окно «Вычисление…», которое появляется при попытке удалить огромный файл или папку с тысячами элементов, скоро может стать менее раздражающим. Microsoft ускорила удаление крупных фрагментированных файлов в Проводнике Windows 11.
Изменение появилось в экспериментальной сборке Windows 11 Insider Preview 26300.8935 от 20 июля.
Компания формулирует улучшение осторожно: удаление стало быстрее лишь в определённых сценариях. Чудес для любой корзины Microsoft пока не обещает.
Больше всего разницу должны заметить владельцы почти заполненных накопителей. Когда свободного места мало, крупный файл нередко записывается не единым блоком, а тысячами фрагментов, разбросанных по диску. При удалении NTFS приходится найти каждый кусок и по очереди освободить занятое им пространство.
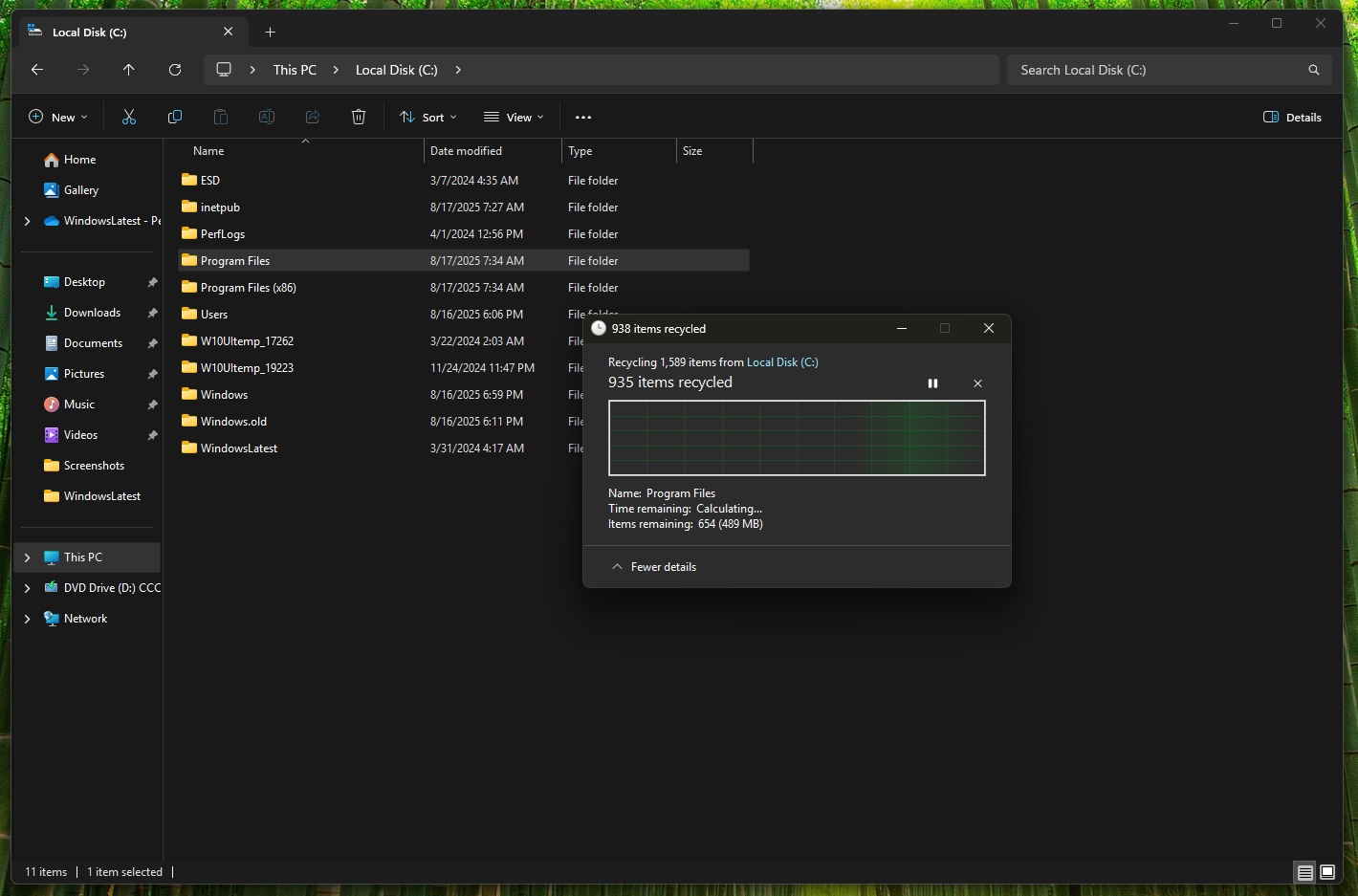
На HDD процесс дополнительно тормозят физические перемещения считывающей головки. Но и SSD не спасает от всей этой бухгалтерии: механики в нём нет, зато файловой системе всё равно приходится разбираться с каждым фрагментом. Microsoft не раскрывает, что именно переписала, однако, вероятно, разработчики ускорили обработку таких операций.
Ещё в июне компания обещала сделать массовое удаление файлов как минимум на 30 % быстрее. Новая сборка стала первым подтверждением того, что работа действительно добралась до тестовой Windows, а не осталась бодрым пунктом в презентации.
Заодно Microsoft ускорила загрузку домашней страницы Проводника и добавила сенсорную прокрутку в раздел «Рекомендуемые». В дальнейшем компания также планирует улучшить поиск по компьютеру и заменить древнее окно «Свойства» современной версией с тёмной темой.
Все изменения распространяются среди участников экспериментального канала постепенно. До стабильной Windows 11 они пока не добрались.



