















В Telegram у части пользователей появилась странная плашка: при попытке оформить цитату мессенджер предлагает оформить подписку Premium. Формально платными в Telegram действительно могут быть некоторые возможности расширенного форматирования и Markdown.
На проблему обратил внимание телеграм-канал «Код Дурова». Но обычные цитаты к премиальным функциям относиться не должны.
Поэтому новая плашка выглядит не как очередная монетизация всего живого, а скорее как техническая ошибка.
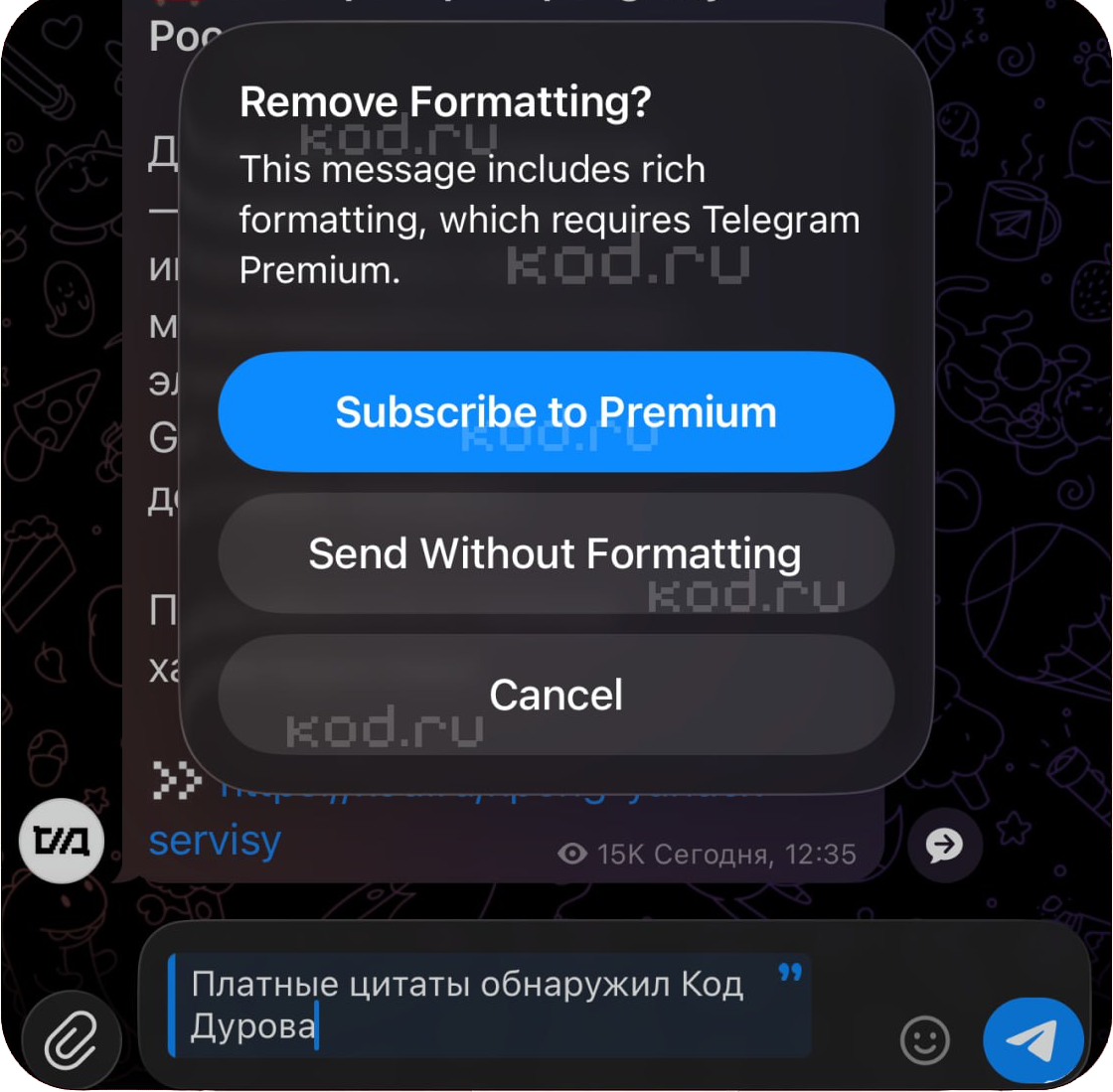
Тем более ограничение уже удалось обойти. Достаточно нажать «Сбросить и отправить» — Send Without Formatting. После этого предупреждение исчезает, а сама цитата в сообщении остаётся.
То есть Telegram пока как будто говорит: «Хотите цитату — платите». Но если нажать соседнюю кнопку, выясняется, что платить всё-таки не обязательно.
Вероятнее всего, речь идёт о баге интерфейса или проверки форматирования, который исправят в одном из следующих обновлений. Официальных пояснений от Telegram на момент публикации нет.
Пока же пользователям доступен простой обходной путь: сбросить форматирование перед отправкой и сохранить цитату без Premium. Монетизация не удалась, по крайней мере, в этот раз.



