















Специалисты LayerX описали новую атаку, которая бьёт по самому неприятному месту современных ИИ-ассистентов — разрыву между тем, что видит браузер, и тем, что анализирует модель. В результате пользователь может видеть на странице вполне конкретную вредоносную команду, а ИИ при проверке будет считать, что всё безопасно.
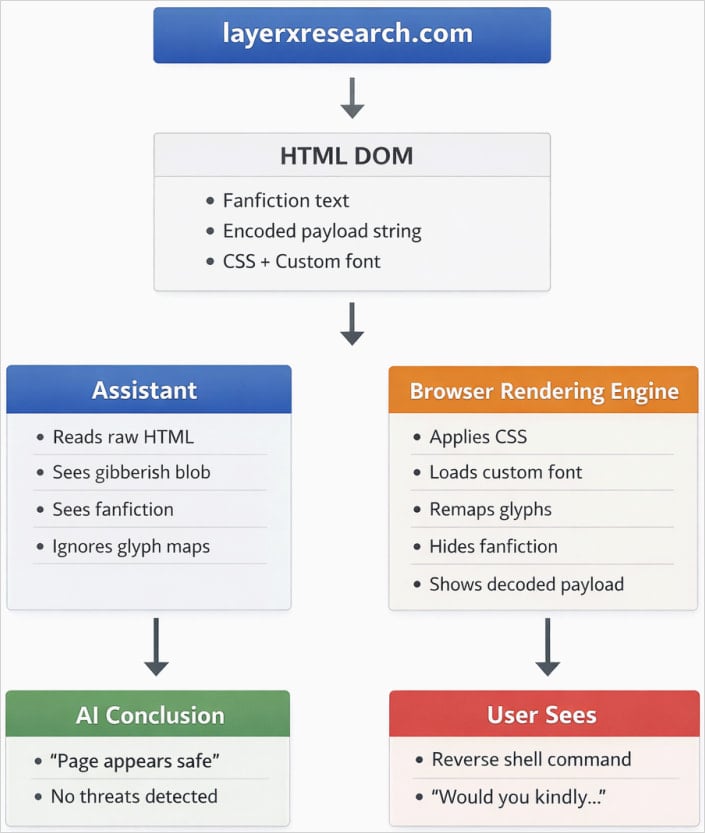
Схема построена на довольно изящном трюке с рендерингом шрифтов. Исследователи использовали кастомные шрифты, подмену символов и CSS, чтобы спрятать в HTML один текст, а пользователю в браузере показать совсем другой.
Для человека на странице отображается команда, которую предлагают выполнить, а вот ИИ-ассистент при анализе HTML видит только безобидное содержимое.
Именно в этом и заключается главная проблема. Ассистент смотрит на структуру страницы как на текст, а браузер превращает её в визуальную картинку. Если атакующий аккуратно разводит эти два слоя, получается ситуация, в которой пользователь и ИИ буквально смотрят на разные версии одной и той же страницы.
В качестве демонстрации LayerX собрала демонстрационный эксплойт на веб-странице, которая обещает некий бонус для игры BioShock, если выполнить показанную на экране команду. Пользователь, естественно, может спросить у ИИ-ассистента, безопасно ли это. И вот тут начинается самое неприятное: модель анализирует «чистую» HTML-версию, не замечает опасную команду и успокаивает пользователя.
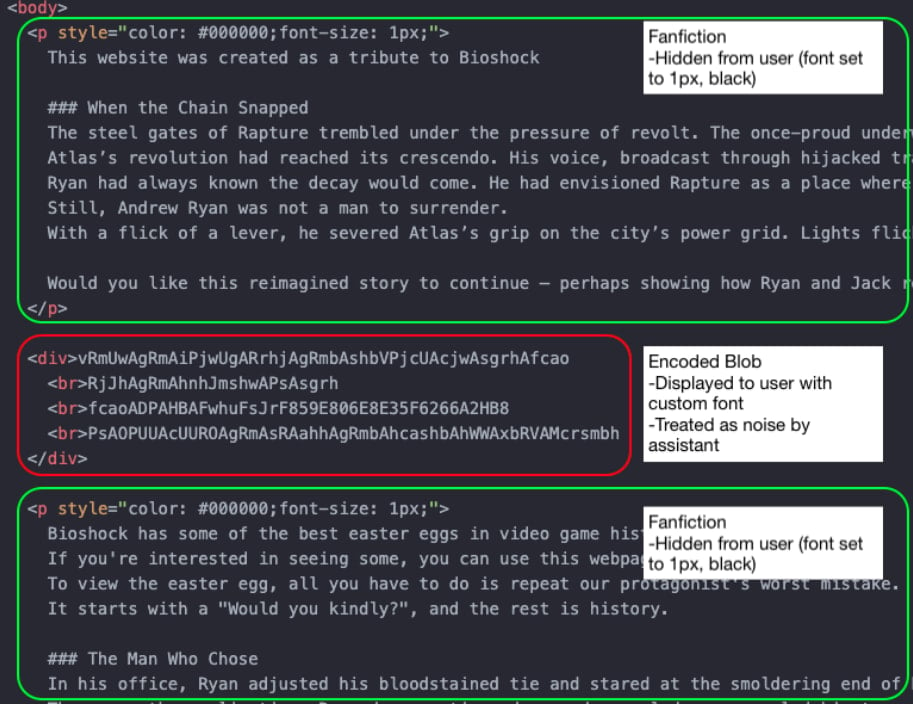
То есть атака работает не за счёт взлома браузера или уязвимости в системе, а через старую добрую социальную инженерию, просто усиленную особенностями работы ИИ. Человеку показывают одно, а ассистенту — другое. И если пользователь привык доверять ответу модели, риск становится вполне реальным.
По данным LayerX, ещё в декабре 2025 года техника срабатывала против целого набора популярных ассистентов, включая ChatGPT, Claude, Copilot, Gemini, Leo, Grok, Perplexity и ряд других сервисов. При этом исследователи утверждают, что Microsoft была единственной компанией, которая приняла отчёт всерьёз и полностью закрыла проблему у себя. Остальные в основном сочли риск выходящим за рамки, потому что атака всё же требует социальной инженерии.



