















В Нижнем Новгороде завершилась XI международная конференция «Цифровая индустрия промышленной России». За четыре дня ЦИПР-2026 посетили более 13 тыс. участников из всех регионов России и 46 стран. На выставке представили 185 стендов, а деловая программа включила 165 дискуссий с участием более 1000 спикеров.
Главными темами стали цифровая трансформация промышленности, технологический суверенитет, импортозамещение ПО, ИИ, кибербезопасность, роботизация и развитие отечественных ИТ-решений. В мероприятии приняли участие представители правительства, региональных властей и крупнейших компаний.
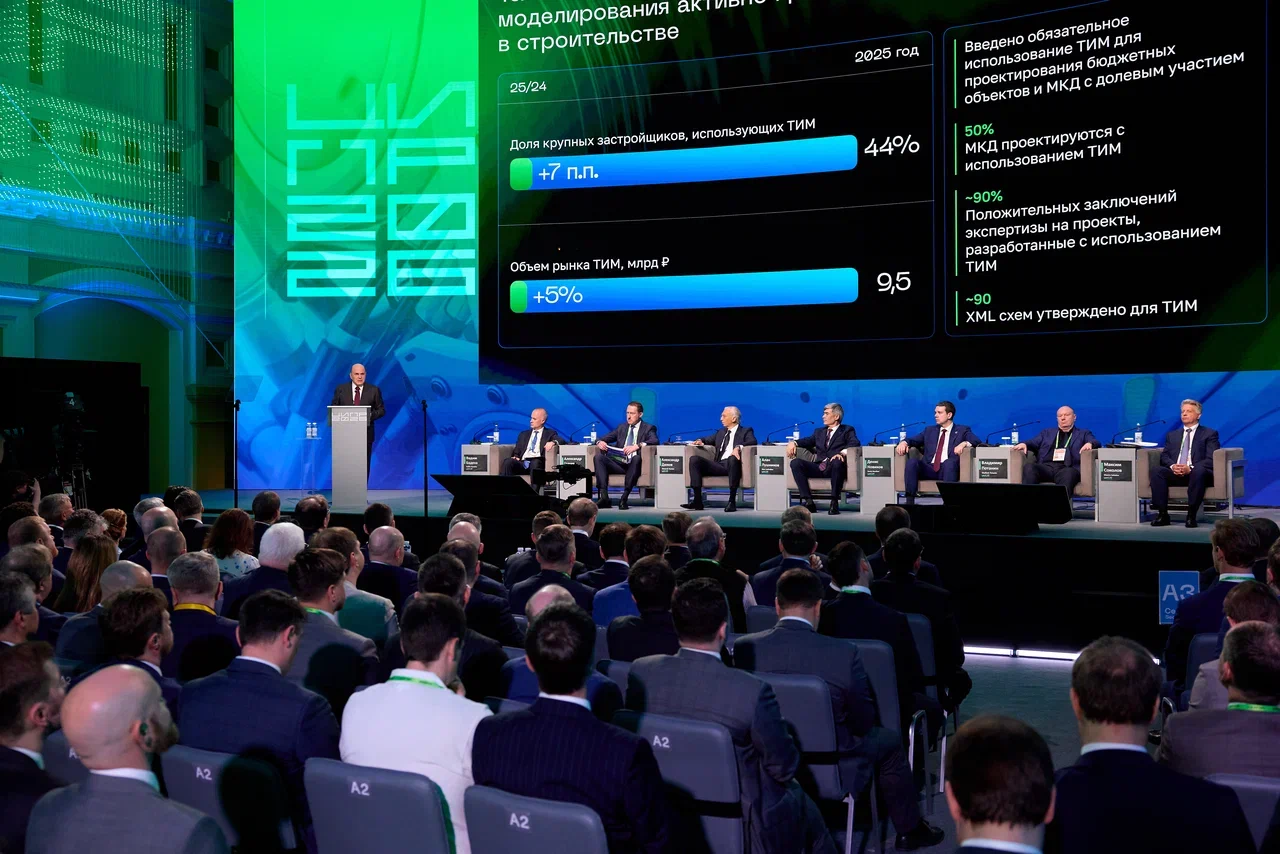
На пленарной сессии премьер-министр Михаил Мишустин заявил, что за шесть лет доля ИТ-отрасли в ВВП удвоилась, а объём продаж российских продуктов и сервисов вырос почти в 4,5 раза и превысил 5 трлн рублей. Также, по его словам, впервые с 2022 года экспорт российского ПО вырос на 15%, а число занятых в отрасли превысило 1 млн человек.

Отдельный блок был посвящён итогам работы индустриальных центров компетенций. По словам вице-премьера Дмитрия Григоренко, из 175 особо значимых проектов, отобранных в 2022 году, уже завершены 120. Более 930 предприятий используют созданные решения, а российским ПО закрыто свыше 180 направлений, где раньше не было отечественных аналогов.
Компании на ЦИПР-2026 тоже показали немало громких новинок. «Группа Астра» объявила о запуске Astra Cloud на отечественных 48-ядерных процессорах Baikal-S. «Ростелеком» представил стратегию развития до 2030 года. Т-Банк провёл контролируемую кибератаку на собственную инфраструктуру с помощью ИИ. «Росатом» показал планшет-трансформер OKO Book 5 Yoga и платформу промышленного ИИ «АтомМайнд 2.0». РЖД и «Бюро 1440» начали проект по оснащению «Сапсанов» и «Ласточек» отечественной спутниковой связью.
Международная часть тоже была заметной: на конференцию приехали более 300 иностранных делегатов, а свои стенды представили 11 зарубежных компаний. За время форума подписали более 350 соглашений, в том числе международные договорённости с Китаем, Лаосом и Анголой.
Помимо деловой программы, на ЦИПР прошла выставка цифрового искусства DeCIPRaland: в ней участвовали 35 художников и более 70 работ из разных стран. Цифровой музей посетили 4200 человек. Также состоялась премия ЦИПР Диджитал, где отметили проекты в области цифровых технологий, ИИ, видеоаналитики, онлайн-банкинга и цифровых двойников.

Формально ЦИПР остаётся конференцией про промышленную цифровизацию, но по факту всё больше напоминает большую витрину российского технологического рынка: тут одновременно обсуждают госполитику, показывают железо, облака, ИИ, роботов, спутниковую связь и договариваются о новых проектах. То есть место, где цифровая экономика перестаёт быть абстрактным словосочетанием и превращается в стенды, соглашения и очереди у павильонов.



