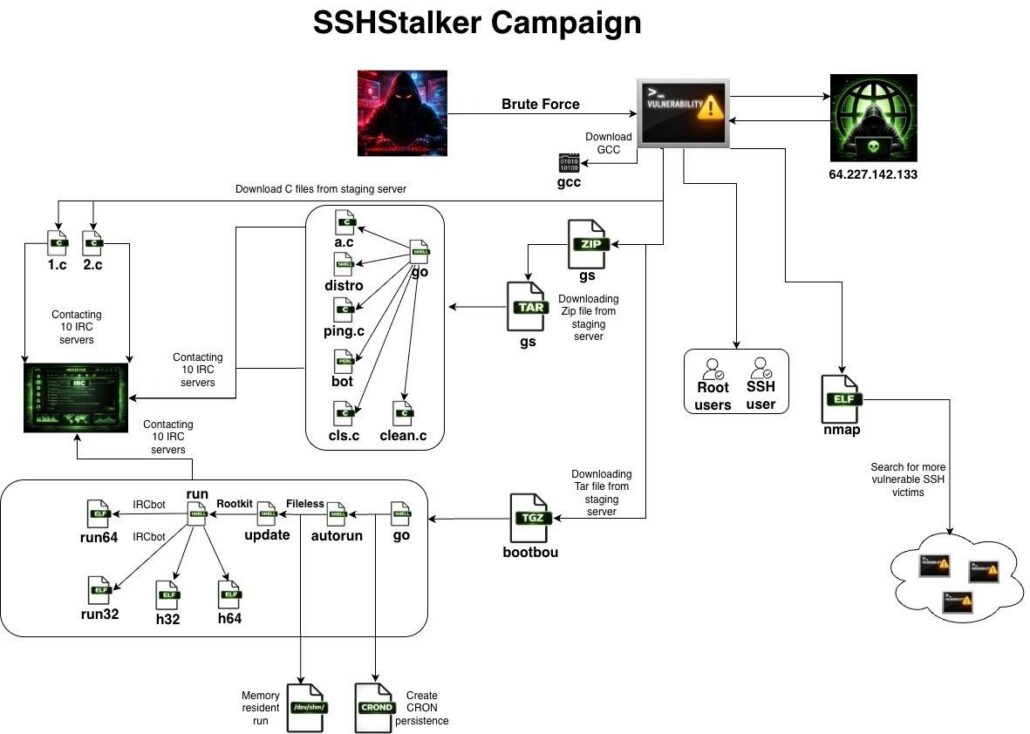
Специалисты по киберразведке из Flare обнаружили Linux-ботнет, операторы которого отдали предпочтение надежности, а не скрытности. Для наращивания потенциала SSHStalker использует шумные SSH-сканы и 15-летние уязвимости, для C2-связи — IRC.
Новобранец пока просто растет, либо проходит обкатку: боты подключаются к командному серверу и переходят в состояние простоя. Из возможностей монетизации выявлены сбор ключей AWS, сканирование сайтов, криптомайнинг и генерация DDoS-потока.
Первичный доступ к Linux-системам ботоводам обеспечивают автоматизированные SSH-сканы и брутфорс. С этой целью на хосты с открытым портом 22 устанавливается написанный на Go сканер, замаскированный под опенсорсную утилиту Nmap.
В ходе заражения также загружаются GCC для компиляции полезной нагрузки, IRC-боты с вшитыми адресами C2 и два архивных файла, GS и bootbou. Первый обеспечивает оркестрацию, второй — персистентность и непрерывность исполнения (создает cron-задачу на ежеминутный запуск основного процесса бота и перезапускает его в случае завершения).
Чтобы повысить привилегии на скомпрометированном хосте, используются эксплойты ядра, суммарно нацеленные на 16 уязвимостей времен Linux 2.6.x (2009-2010 годы).
Владельцы SSHStalker — предположительно выходцы из Румынии, на это указывает ряд найденных артефактов.
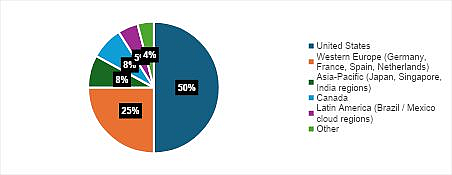
Исследователи также обнаружили файл со свежими результатами SSH-сканов (около 7 тыс. прогонов, все за прошлый месяц). Большинство из них ассоциируются с ресурсами Oracle Cloud в США, Евросоюзе и странах Азиатско-Тихоокеанского региона.