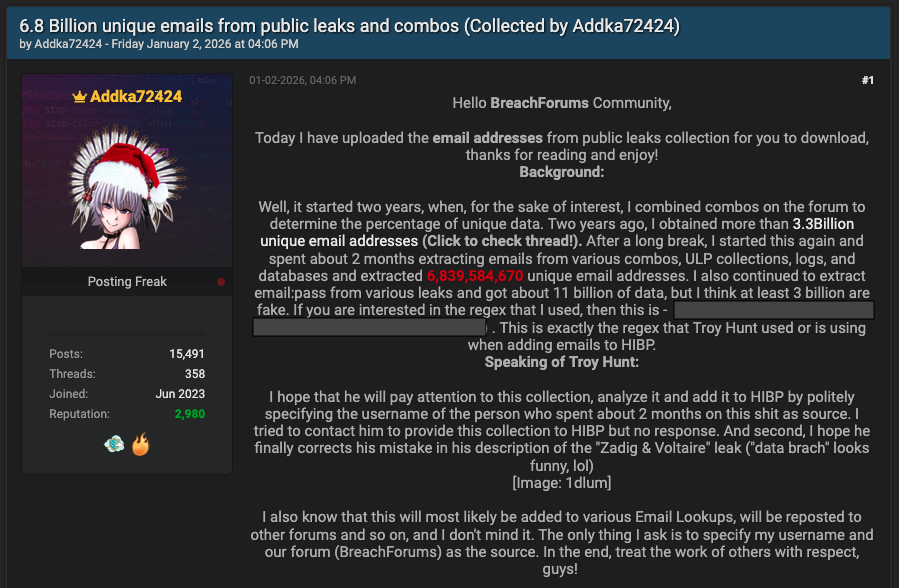
На одном из популярных форумов для киберпреступников появился интересный пост: пользователь под ником Adkka72424 заявил, что собрал базу из 6,8 млрд уникальных адресов электронной почты. По его словам, на это ушло несколько месяцев; он выгружал данные из логов инфостилеров, ULP-коллекций и различных баз, циркулирующих в Сети.
Цифра звучит почти фантастически. Однако исследователи Cybernews изучили массив объёмом около 150 ГБ и пришли к несколько иным выводам.
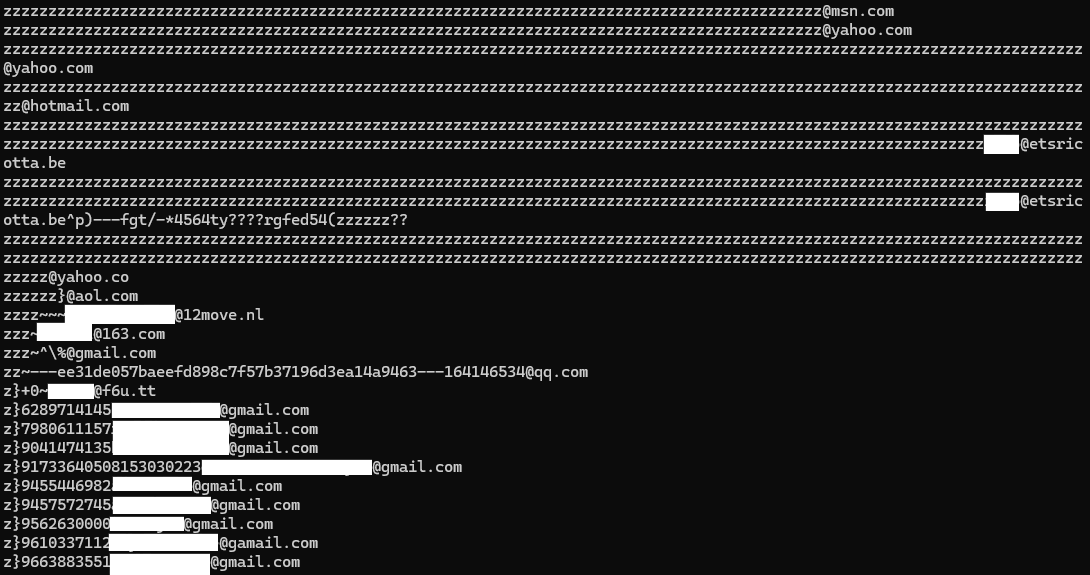
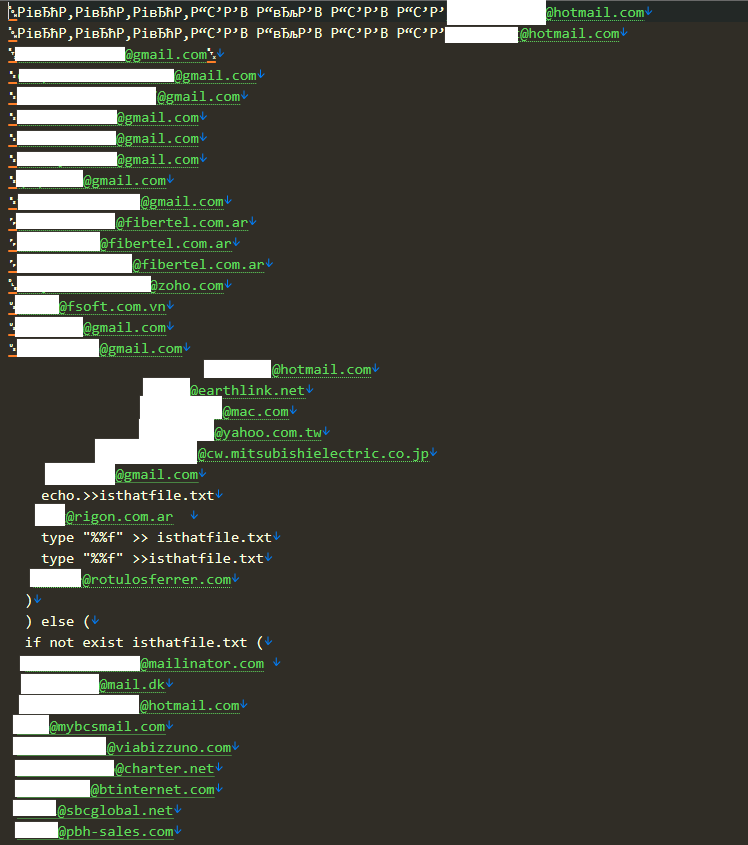
Формально автор не соврал: в файле действительно более 6,8 млрд строк. Но внутри оказалось множество дубликатов и откровенно невалидных адресов. После «очистки» реальное количество рабочих имейлов, по оценке экспертов, может составлять около 3 млрд.
Даже если это «всего лишь» 3 млрд, масштаб всё равно впечатляющий. В эпоху автоматизации фишинговых кампаний и атак вида «credential stuffing» объём решает многое. При конверсии всего 0,001% из трёх миллиардов злоумышленники теоретически могут получить около 30 тысяч потенциальных жертв. Для массовых рассылок этого более чем достаточно.
Сам автор публикации утверждает, что хотел «повысить осведомлённость» и привлечь внимание эксперта по утечкам Троя Ханта. Параллельно он дал традиционный совет пользователям: сменить пароли и включить двухфакторную аутентификацию. Впрочем, по комментариям на форуме видно, что аудитория интересуется базой прежде всего как инструментом для кросс-проверки других утечек: сопоставляя записи, злоумышленники могут быстрее находить «свежие» скомпрометированные аккаунты и экономить время.