














Если на Windows 11 внезапно пропало место на системном диске, а директория с мемами и загрузками ни при чём, виновником может оказаться неочевидный системный файл. Windows Latest выяснил, что файл CapabilityAccessManager.db-wal способен разрастаться до десятков и даже сотен гигабайт, тихо забивая диск C:.
Речь идёт о файле по пути:
C:\ProgramData\Microsoft\Windows\CapabilityAccessManager\CapabilityAccessManager.db-wal
Он связан со службой Capability Access Manager, которая отвечает за разрешения приложений: доступ к камере, микрофону, геолокации, записи экрана и другим настройкам приватности. В норме такой файл должен весить пару мегабайт. Но из-за бага он может начать пухнуть как на дрожжах.
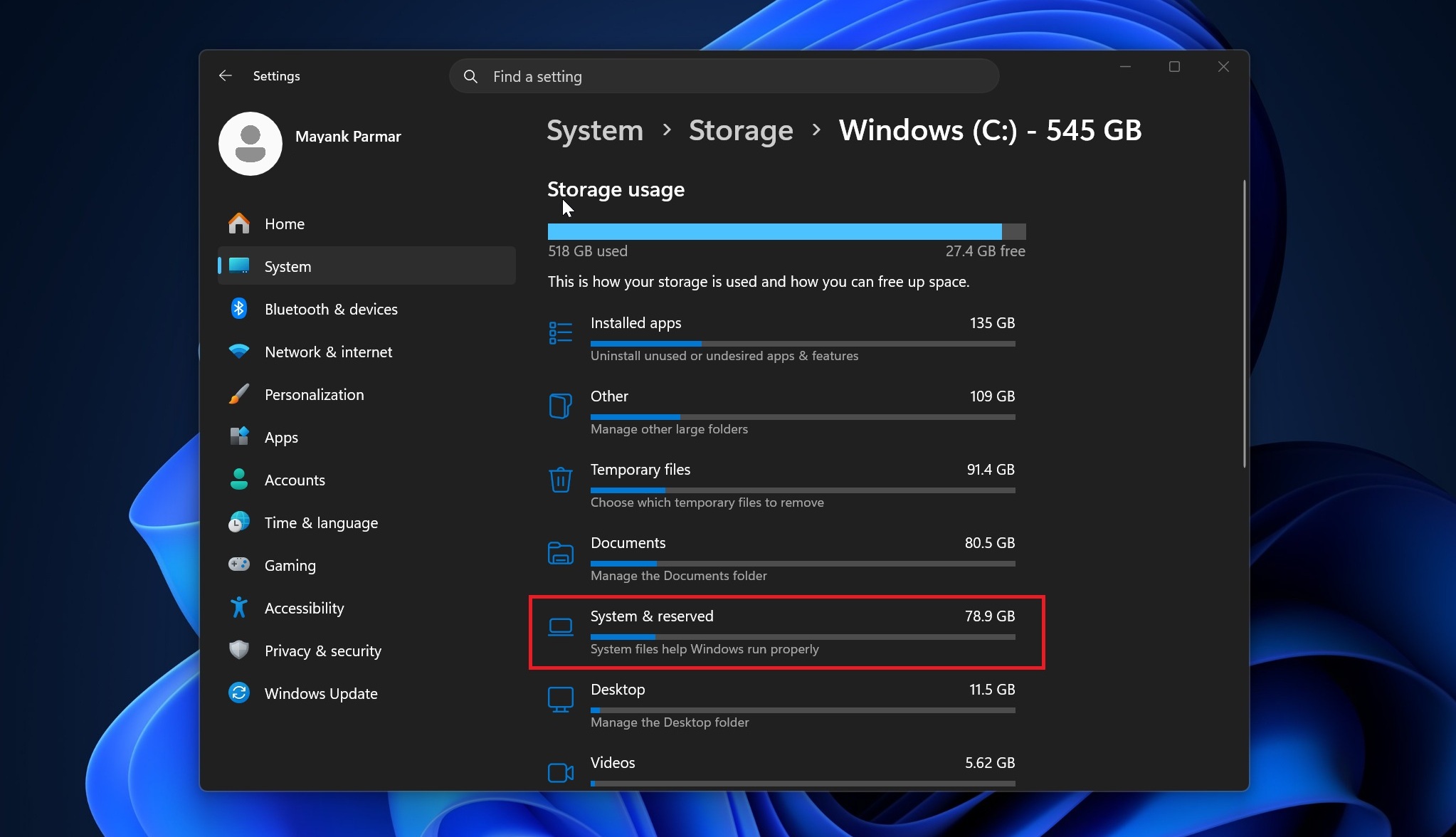
По данным Windows Latest и жалобам пользователей, размер CapabilityAccessManager.db-wal доходил до 70, 110, 200 и даже 513 ГБ. При этом Windows не показывает проблему напрямую: в настройках всё прячется в разделе «System & reserved» или «System files».
Microsoft уже признала проблему в примечаниях к обновлению Windows 11 KB5095093. Компания указала, что апдейт улучшает использование дискового пространства для CapabilityAccessManager.db-wal. Исправление должно попасть в обязательный набор обновлений Patch Tuesday 14 июля 2026 года и выйти сразу для всех пользователей.
Проверить себя можно через Настойки → Система → Память → Системные и зарезервированные. Если раздел внезапно занимает подозрительно много места, стоит посмотреть размер папки CapabilityAccessManager с помощью WizTree, TreeSize или WinDirStat, запущенных от имени администратора.
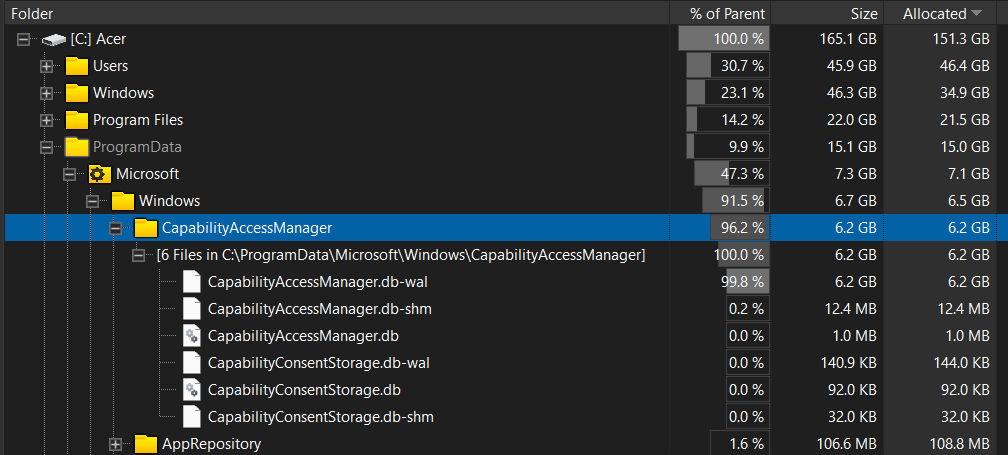
Если CapabilityAccessManager.db-wal весит несколько мегабайт — всё нормально. Если уже несколько гигабайт и продолжает расти — поздравляем, Windows решила устроить склад логов у вас на диске. Самый безопасный вариант — дождаться июльского патча. Удалять системные файлы вручную лучше не стоит: Windows и без вашей помощи умеет создавать приключения.



