














Исследователи проверили 281 популярное бесплатное VPN-приложение из Google Play и выяснили неприятный, но закономерный факт: многие из них проваливают базовую задачу VPN — защищать трафик пользователя. Проблемные приложения суммарно установили более 2,4 млрд раз.
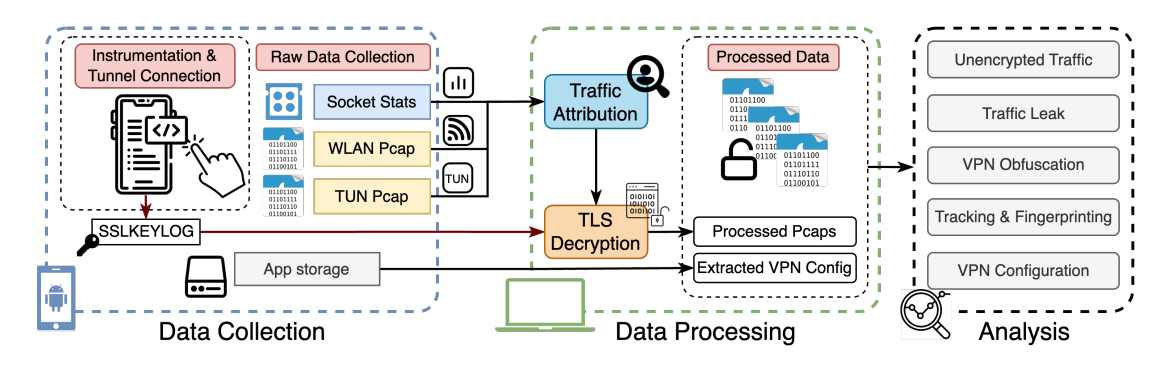
Проверку провели (PDF) специалисты Мичиганского университета, Университета Нью-Мексико и IIT Delhi с помощью системы MVPNalyzer.
Она создана для регулярного аудита VPN для Android и показывает, что у части таких сервисов приватность существует скорее в описании, чем в реальности.
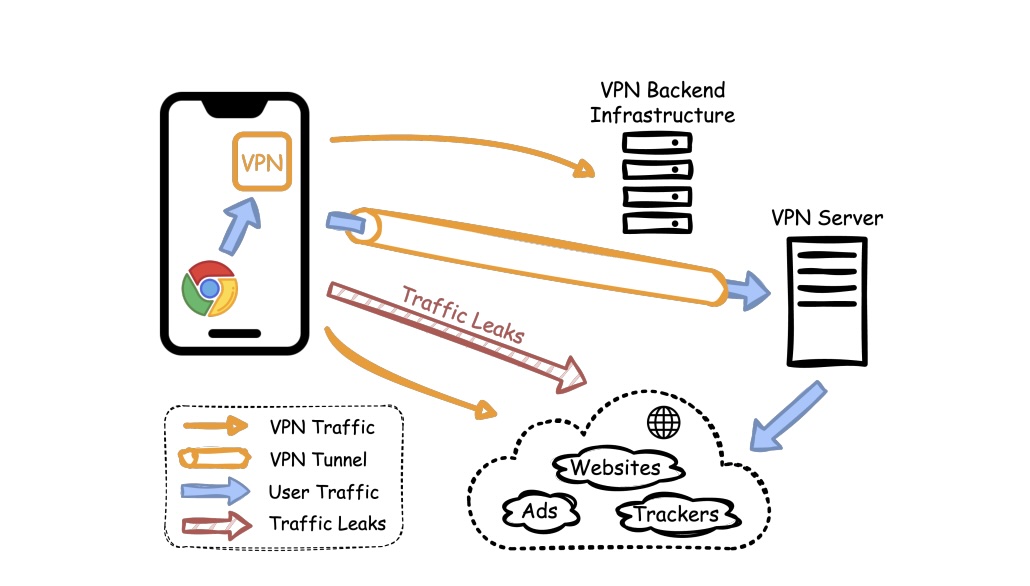
У 29 приложений трафик утекал мимо зашифрованного туннеля. В 24 случаях наружу уходили DNS-запросы, по которым видно, какие сайты открывает пользователь.
Ещё шесть приложений пропускали полноценный веб-трафик вне туннеля, а четыре вообще работали без шифрования. Отличный VPN, если ваша цель — чтобы вас было видно всем.
Самая неприятная находка — пять приложений, которые скачивали конфигурационные файлы без шифрования. Такой файл сообщает приложению, к какому серверу подключаться. Если его можно перехватить и подменить, атакующий в той же сети, например в публичном Wi-Fi, способен перенаправить VPN-подключение на свой сервер. Пользователь увидит привычное «connected», а весь трафик пойдёт через чужие руки.

Слежка тоже никуда не делась. 76 приложений отправляли рекламный идентификатор устройства, а 246 связывались с известными рекламными и трекинговыми серверами. Некоторые передавали модель телефона, версию ОС, размер экрана и другие данные, из которых легко собрать цифровой отпечаток. Одно приложение, по данным исследования, отправляло даже точные GPS-координаты.
Отдельный сюрприз — слабые настройки OpenVPN. Из 108 разобранных конфигураций только одна соответствовала всем проверенным практикам безопасности. Встречались устаревшие шифры вроде Blowfish и 3DES, а в отдельных случаях шифрование фактически отключалось.



