















Microsoft нашла новое применение для клавиши Copilot — не делать вообще ничего. В экспериментальных сборках Windows 11 обнаружили настройку Do nothing, которая позволяет полностью отключить кнопку запуска ИИ-помощника на совместимых компьютерах.
Новую опцию заметил энтузиаст под ником phantomofearth. Она появилась в разделе «Bluetooth и устройства» → «Клавиатура» рядом с другими вариантами переназначения клавиши.
Сейчас на неё можно повесить запуск Microsoft 365 Copilot, поиск или пользовательское действие.
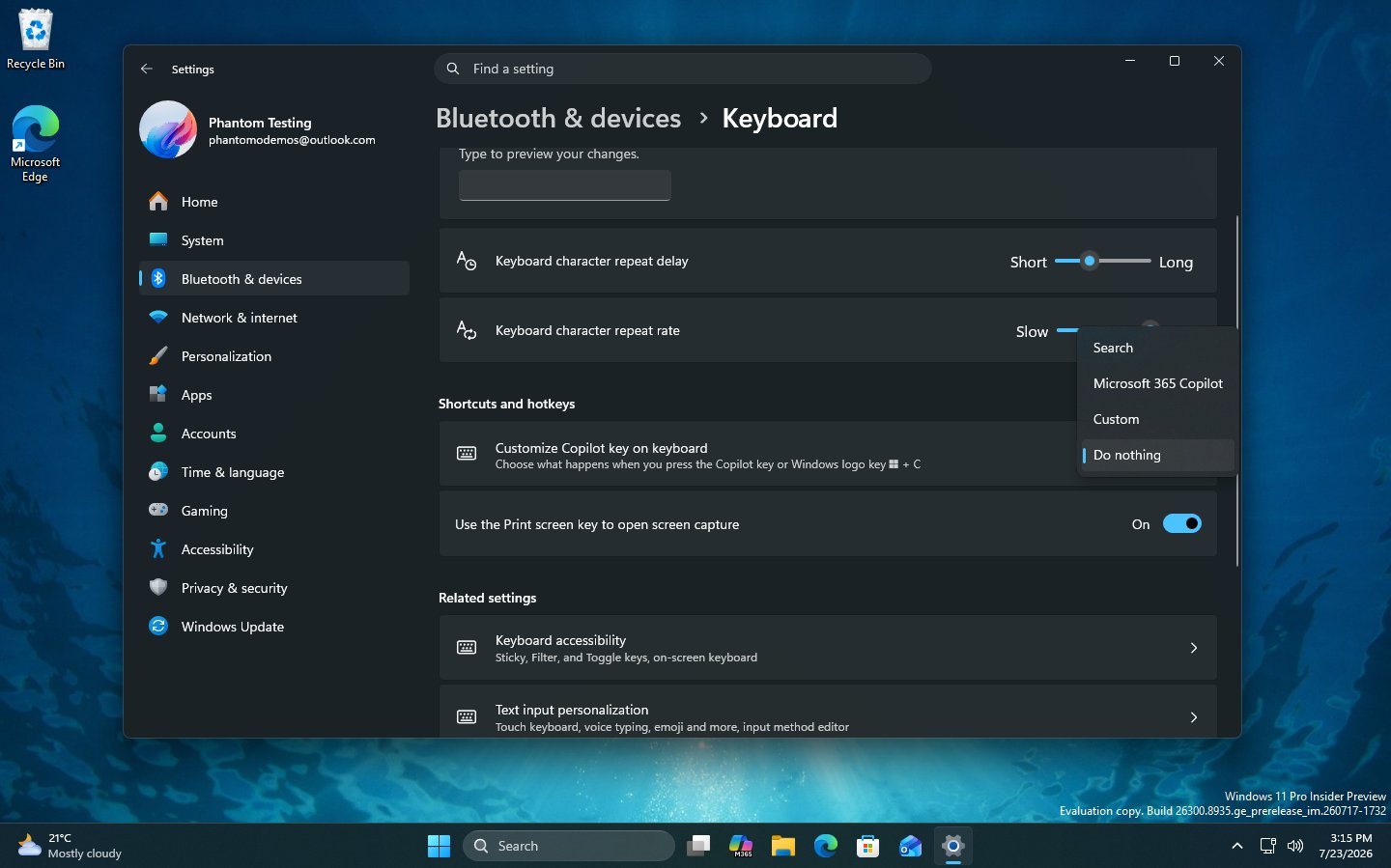
Функция пока доступна не всем участникам тестирования. Некоторые пользователи утверждают, что получили её раньше, тогда как на других компьютерах настройка отсутствует. Вероятно, Microsoft развёртывает нововведение поэтапно.
Клавиша Copilot появилась на новых Windows-ноутбуках в 2024 году. Производителям предложили заменить ею правый Ctrl, чтобы подчеркнуть наступление эпохи ИИ-компьютеров.
Правда, объяснить покупателям, чем такие машины принципиально лучше обычных мощных ПК, получилось не слишком убедительно.
В мае 2026 года Microsoft уже начала сдавать позиции: компания пообещала разрешить возвращать кнопке функцию правого Ctrl, хотя и с ограничениями. До этого пользователям приходилось обращаться к сторонним решениям вроде NoCopilotKey, чтобы случайное нажатие не вызывало ИИ-помощника.
Теперь отключить кнопку можно будет штатными средствами, если настройка доберётся до стабильной Windows 11.
Copilot продолжает проникать в Проводник и другие части системы, но хотя бы одна дверь перед ним наконец сможет остаться закрытой.



