








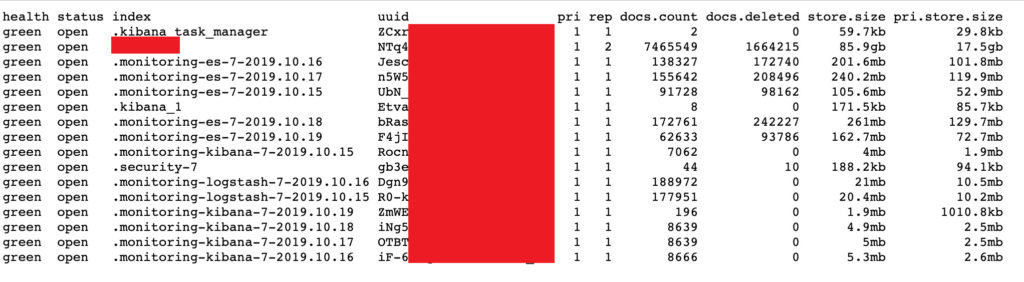







«Сбер» с 1 сентября 2026 года прекратит обслуживание валютных и мультивалютных карт Visa, сообщает СМИ со ссылкой на СМС-рассылку банка. Речь идёт в том числе о картах, срок действия которых ранее продлили до 2030 года. Далеко они не уехали.
Клиентам рекомендовали заранее закрыть такие карты и перевести оставшиеся деньги на другие счета.
Сделать это можно в приложении «Сбербанк онлайн»: потребуется открыть раздел управления картами, выбрать нужную карту и запустить процедуру закрытия. Тем, кто не пользуется приложением, придётся обратиться в отделение банка.
Самостоятельное закрытие карт должно помочь клиентам сохранить доступ к средствам и избежать задержек после 1 сентября. Заодно банку не придётся собирать в офисах очереди из владельцев внезапно устаревшего пластика.
Решение принято на фоне постепенного вывода Visa и Mastercard из российского оборота. В начале июля глава Банка России Эльвира Набиуллина заявила, что процесс продолжается, однако регулятор пока не устанавливает окончательный срок отказа от международных карт.
В мае директор департамента Национальной платёжной системы ЦБ Алла Бакина говорила, что Visa и Mastercard должны покинуть российский рынок. После ухода платёжных систем из страны карты перестали выполнять прежние функции, а Национальная система платёжных карт продолжает тратить деньги на их поддержку.
По словам Бакиной, за последние четыре-пять лет доля Visa и Mastercard в России сократилась до менее чем 17%. Банки заменяют их другими инструментами, прежде всего картами «Мир», а НСПК подталкивает старый пластик к выходу экономическими методами.



