В Сети обнаружена новая интересная мошенническая кампания. Стоящие за ней злоумышленники используют личность Илона Маска и взломанные аккаунты Twitter, их дневная выручка составила 28 биткинов (или 180 000 долларов).
Мошенники начинали свою схему со взлома любой подтвержденной учетной записи Twitter, после чего меняли ее имя на «Elon Musk». Далее злоумышленники размещали от лица Маска информацию о «крупнейшей в истории раздаче биткоинов» — 10 000 цифровых монет.
«Я раздаю 10 000 биткоинов (BTC) сообществу», — гласил взломанный аккаунт.
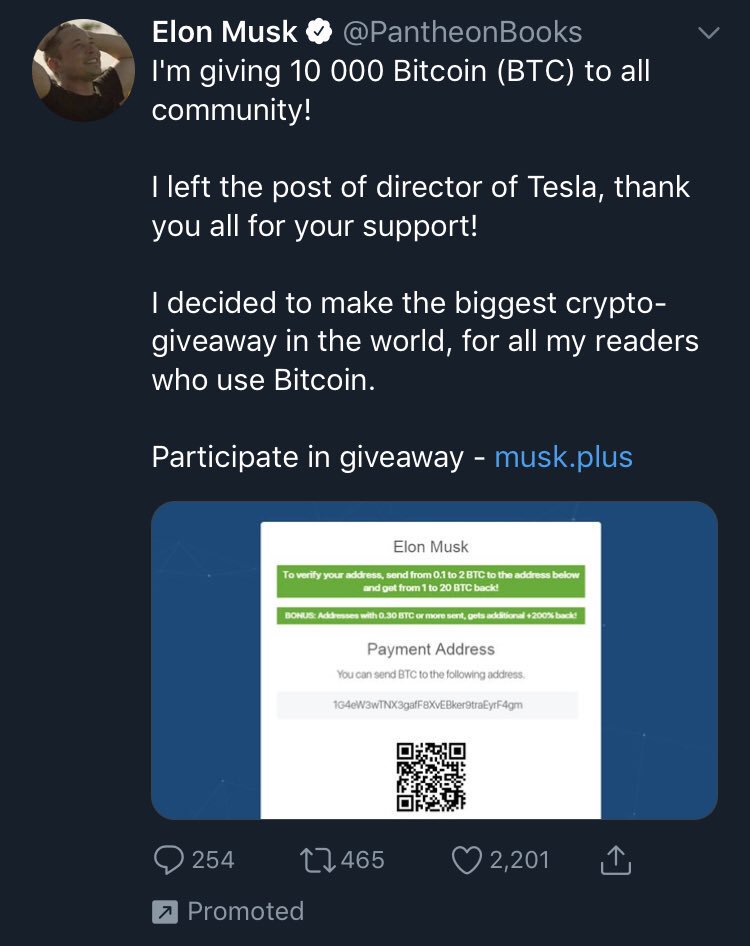
Хуже всего, что подобный пост даже продвигался с помощью рекламной системы Twitter. Это позволило охватить большую аудиторию доверчивых пользователей, а также придать твиту легитимность.
Также мошенники размещали информацию о сайтах musk[.]plus, musk[.]fund и spacex[.]plus, на них пользователи должны были отправить от 0,1 до 3 биткоинов, чтобы получить в ответ гораздо больше.
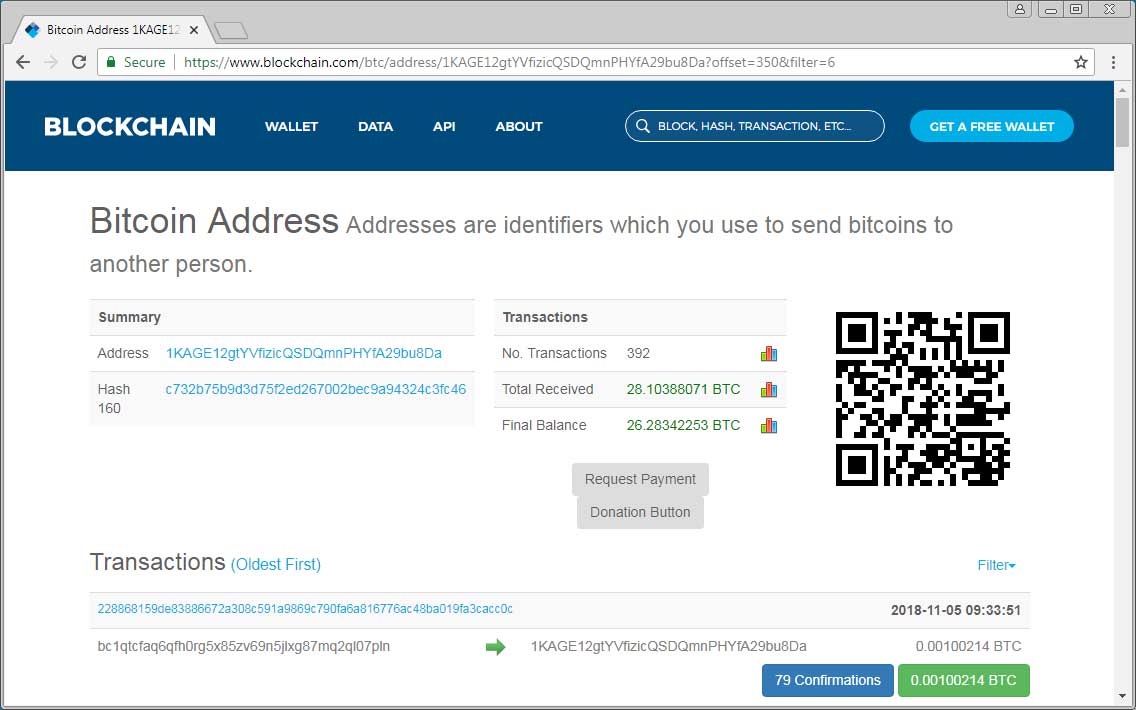
Удивительно, но за всего один лишь день мошенники получили 392 транзакций, что позволило им заработать 28 биткоинов или 180 000 в долларах США.
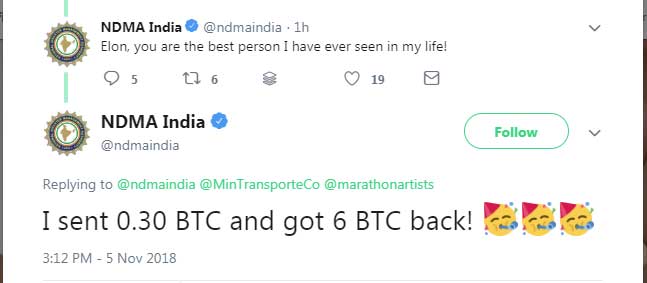
В целях продвижения своей кампании злоумышленники также взломали Twitter-аккаунт Министерства транспорта Колумбии и Национального управления по ликвидации последствий стихийных бедствий Индии.
С их помощью мошенники пытались убедить пользователей, что цифровая валюта действительно возвращается.