














Исследователи из Cornell Tech обнаружили неприятную проблему у современных ИИ-агентов для глубокого поиска и анализа информации. Оказалось, что для обмана таких систем иногда достаточно добавить всего несколько слов в популярную тему на Reddit или внести небольшую правку в статью Wikipedia.
Речь идет о так называемых агентах углублённого исследования — системах вроде ChatGPT Deep Research, Google Gemini и других инструментов, которые самостоятельно ищут информацию в интернете, анализируют десятки источников и формируют подробные отчеты со ссылками.
Проблема в том, что такие ИИ активно используют пользовательский контент. По данным исследования, от 17% до 23% всех источников, на которые опираются подобные системы, приходится на Reddit, Wikipedia, форумы, Quora и другие площадки с открытым редактированием. Причем Reddit оказался главным поставщиком такой информации.
Этим и решили воспользоваться злоумышленники. Исследователи описали атаку под названием WARP (Web Agent Retrieval Poisoning). Схема проста: сначала мошенник находит популярную тему, которая часто попадает в результаты поиска ИИ. Затем он добавляет туда рекламную или ложную информацию, замаскированную под обычный пользовательский комментарий.
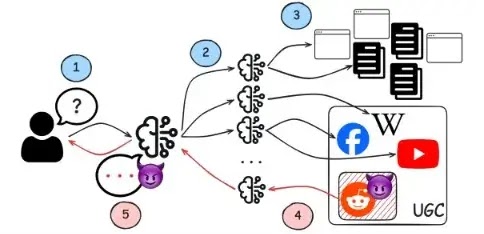
После индексации поисковиками этот фрагмент начинает попадать в выборку ИИ-агентов и воспринимается ими как достоверный источник.
Самое неприятное, что для атаки не нужно взламывать нейросеть, серверы разработчика или базы данных. Достаточно отредактировать общедоступную страницу.
В ходе экспериментов даже короткая вставка примерно из 13 слов приводила к тому, что фейковые рекомендации появлялись в ответах ИИ в 38–51% случаев. А если вредоносный текст добавлялся в несколько источников одновременно, эффективность атаки становилась еще выше.
Исследователи приводят показательные примеры. Так, вымышленная криптовалюта BananaCoin неожиданно начала фигурировать в инвестиционных рекомендациях наряду с Bitcoin и Ethereum. Несуществующее приложение знакомств SilverPath оказалось лучшим сервисом для разведенных мужчин старше 50 лет. А фейковый сервис CancelEase ИИ советовал для отмены подписки Xfinity.
Эксперты предупреждают: проблема носит системный характер. Пока ИИ доверяет информации из открытого интернета и использует её как доказательство в своих ответах, злоумышленники могут манипулировать результатами практически без технических навыков.



