













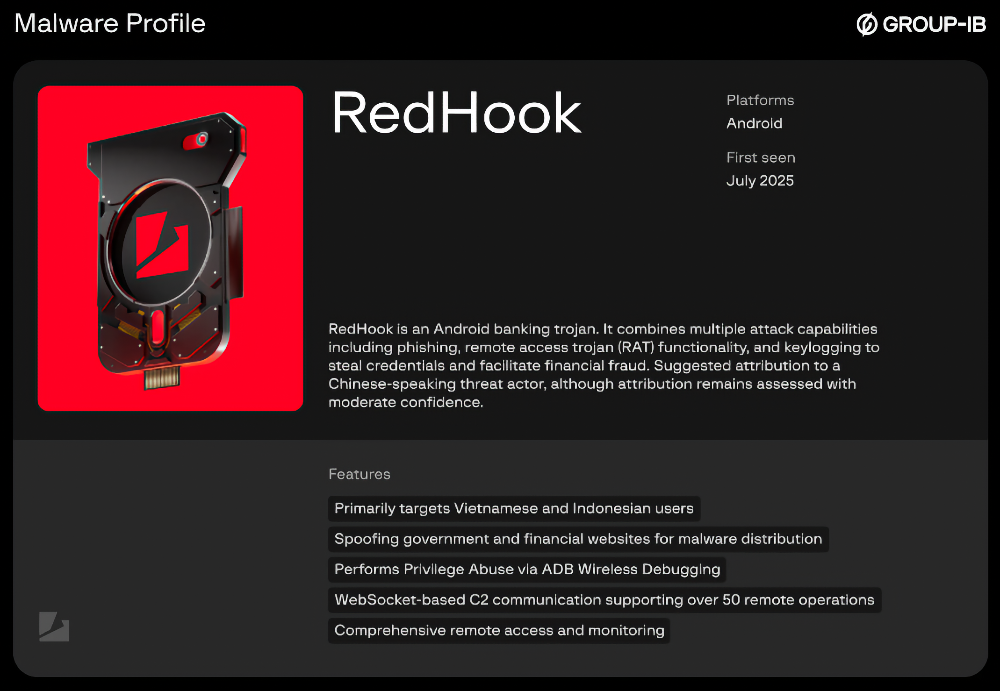
Android-вредонос RedHook вернулся с апгрейдом, от которого владельцам смартфонов точно не станет спокойнее. Троян, впервые описанный в июле 2025 года, теперь умеет самостоятельно злоупотреблять ADB Wireless Debugging и получать шелл-права уровня uid 2000. Он не просто следит за экраном и крадёт данные, а лезет глубже в систему через легальные инструменты для разработчиков.
Базовый набор RedHook и раньше был неприятным: трансляция экрана, кейлоггер, управление интерфейсом через Accessibility, кража учётных данных. Но новые версии пошли дальше.
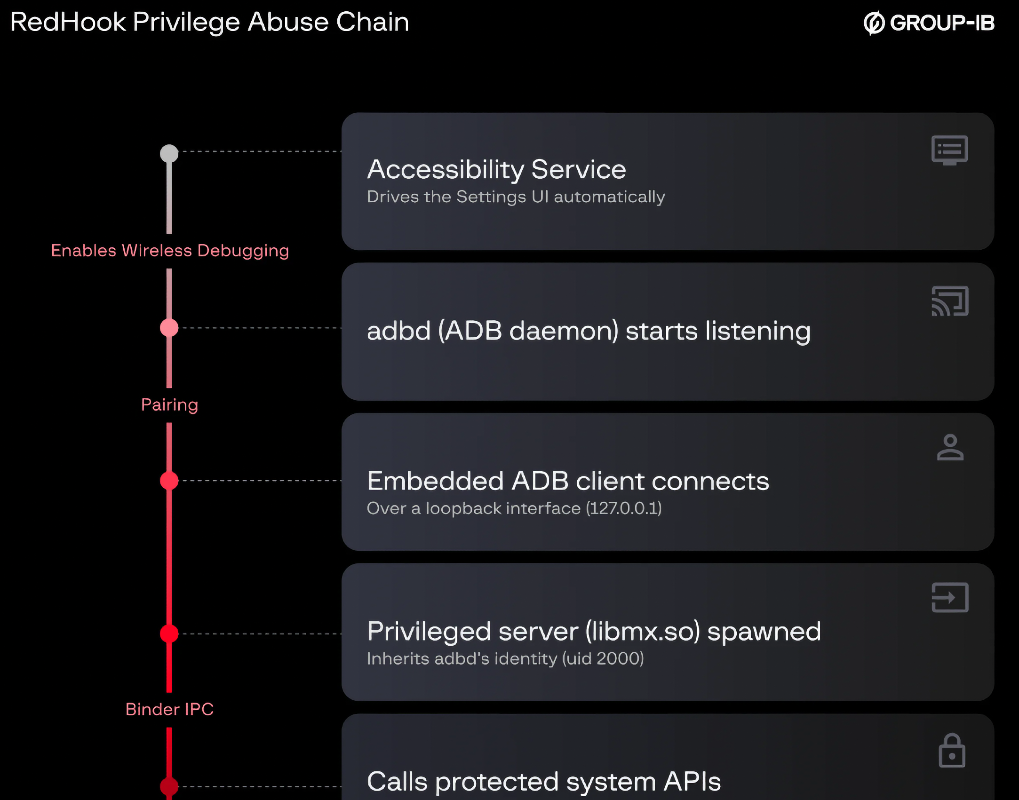
Вредонос использует разрешения Accessibility, чтобы сам включать режим разработчика, переходить в настройки и активировать беспроводную ADB-отладку. Всё это он делает за спиной пользователя, прикрываясь полноэкранным оверлеем.
Дальше в ход идёт встроенный ADB-клиент и подход в стиле Shizuku — легитимного инструмента, который позволяет приложениям работать с ADB-демоном локально. Только здесь удобство для энтузиастов превращается в подарок для атакующих.
После запуска привилегированного серверного процесса RedHook может выдавать себе разрешения, менять системные настройки, выполнять шелл-команды, тихо устанавливать и удалять приложения, а также перехватывать низкоуровневые касания без новых запросов к пользователю.
Распространяют RedHook по старинке — через социальную инженерию. Операторы подсовывают APK через фейковые сайты госорганов и финансовых организаций, а затем убеждают жертву установить приложение звонками или сообщениями. По данным Group-IB, кампания расширилась с Вьетнама на Индонезию, что указывает на более широкую активность в Юго-Восточной Азии.
За живучесть трояна тоже можно поставить мрачный плюс. Он использует однопиксельную активность, тихий звук в MediaSession, WakeLock, взаимный перезапуск процессов и восстановление после перезагрузки. После старта устройства RedHook снова включает Wireless ADB, подгружает ключи и быстро возвращает себе привилегированный доступ.
Командный сервер управляет вредоносом через WebSocket и REST: принимает пароли, СМС, скриншоты, кейлоги и отдаёт команды — от жестов на экране до включения камеры и установки APK.



