Специалисты «Информзащиты» представили новый аналитический отчет по уязвимостям различного класса, выявленным в течение 2015 года в ходе проведенных тестов на проникновение в организациях финансового сектора, ритейла, госучдержениях и телекоме.
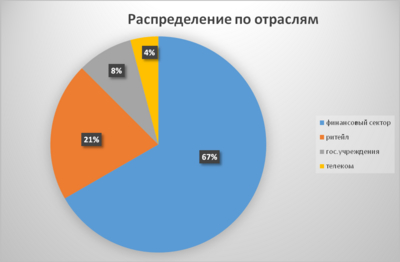
В ходе анализа защищенности информационных систем подавляющее количество уязвимостей было выявлено в финансовом секторе (67%), почти в 3 раза меньше – в ритейле (21%), чуть меньше – в госсекторе и телекоме (8% и 4% соответственно).
Александр Гореликов, руководитель отдела анализа защищенности компании «Информзащита»:
«Выполненные проверки позволили выявить множество слабых мест в информационных системах заказчиков, но при этом позволили своевременно устранить выявленные уязвимости. При этом 29% клиентов подвергались целенаправленным атакам при помощи средств социальной инженерии, что говорит о неизменно низком уровне осведомленности бизнес-пользователей в области ИБ».
Уязвимости публичных веб-приложений (внешний периметр) по классификации международной организации OWASP
 по классификации международной организации OWASP")
Как мы видим, наиболее распространенной уязвимостью является Cross-Site Scripting (межсайтовый скриптинг), позволяющая совершать атаки на пользователей приложений. Данный тип уязвимости был выявлен у 25% клиентов.
Второй по популярности стала уязвимость Security Misconfiguration, небезопасная конфигурация веб-приложения или его окружения, которая была обнаружена более чем у 20% клиентов.
По сравнению с предыдущим годом, в топ также попали две новые уязвимости. Sensitive Data Exposure - хранение и передача «критичных данных» в открытом виде. Injection – возможность внедрения вредоносного подзапроса в легитимный запрос к серверу с последующим чтением/модификацией данных, вплоть до компрометации сервера.
Уязвимости сетевого уровня

Тенденция прошлого года сохранилась – уязвимости практически не изменились, однако их распространенность к атаке STP Claiming Root Role возросла почти в три раза и была выявлена у 59% клиентов.
В свою очередь, распространенность уязвимостей к атаке ARP Cache Poisoning, позволяющая внутреннему нарушителю реализовать атаку Man-In-The-Middle, возросла на 6% и встречалась в этом году в более чем в 66% случаях.
Уязвимости уровня приложений

Среди уязвимостей приложений лидерами являются «Использование учетных записей по умолчанию» и «SNMP-community строки по умолчанию», выявленные у 50% клиентов.
На втором месте по распространенности (46%) уязвимости протокола SSLv3 – «POODLE» и криптографического пакета OpenSSL – «MS14-066». Последняя более известна как «Winshock», и в прошлом году встречалась гораздо реже.
Остальные, менее значимые, но при этом достаточно распространенные:
- недоверенный сертификат SSL;
- множественные уязвимости в веб сервере Apache версии 2.2 < 2.2.28;
- уязвимость Oracle TNS Listener Poison.
С наиболее распространенными уязвимостями, выявленными в 2014 году, можно ознакомиться здесь: http://www.infosec.ru/news/7892
Данные для отчета предоставлены Кириллом Николаевым, специалистом отдела анализа защищенности компании «Информзащита».