













Пока пользователи и специалисты спорят о причинах проблем с доступом к отдельным сайтам, в Сети уже начали появляться народные рецепты борьбы с блокировками. Пользователь Хабра под ником eByeBots рассказал о необычном способе восстановления доступа к некоторым ресурсам через браузеры на базе Chromium.
По его словам, решение связано не с VPN или прокси, а с изменением параметров TLS-шифрования в самом браузере.
Автор рекомендует открыть страницу экспериментальных настроек Chrome (chrome://flags/) или аналогичный раздел в других Chromium-браузерах и найти параметр Cryptography Compliance (CNSA).
После его активации браузер начинает отдавать приоритет криптографическим алгоритмам из американского стандарта CNSA.
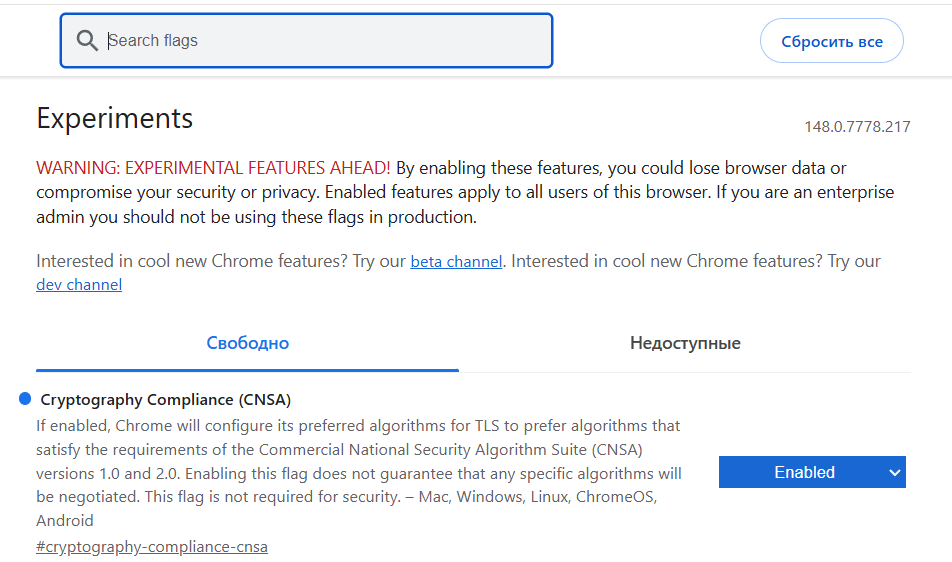
На практике это меняет TLS-отпечаток браузера — набор параметров, который формируется во время установки защищённого соединения с сайтом.
По словам автора публикации, именно после включения этого режима ему удалось восстановить доступ к ряду ресурсов, включая сайт хостинг-провайдера Beget, где ранее наблюдались проблемы с подключением к CDN.
Для упрощения процедуры энтузиаст даже выложил на GitHub готовый BAT-файл, который позволяет применить необходимые настройки в один клик.
Интересно, что опубликованное решение появилось на фоне многочисленных сообщений о сбоях при доступе к различным сайтам и сервисам. Ранее исследователи уже высказывали предположения, что некоторые ограничения могут учитывать параметры TLS ClientHello и так называемые TLS-фингерпринты браузеров.
Если эта гипотеза верна, то изменение криптографических настроек действительно способно повлиять на прохождение соединения через сетевые фильтры.
Впрочем, пока речь идёт исключительно о наблюдениях отдельных пользователей, а не о подтверждённом универсальном способе обхода ограничений. Сам автор подчёркивает, что продолжает тестирование метода на разных провайдерах и в различных сценариях.



