Управление по организации борьбы с противоправным использованием информационно-коммуникационных технологий МВД России (УБК МВД) предупреждает об изменении ранее известной схемы кражи аккаунтов в мессенджерах. На этот раз злоумышленники ориентируются на пользователей отечественного МАКС.
Как сообщает УБК МВД в официальном телеграм-канале «Вестник киберполиции России», наиболее активно мошенники действуют в группах, где родственники ищут пропавших без вести военнослужащих.
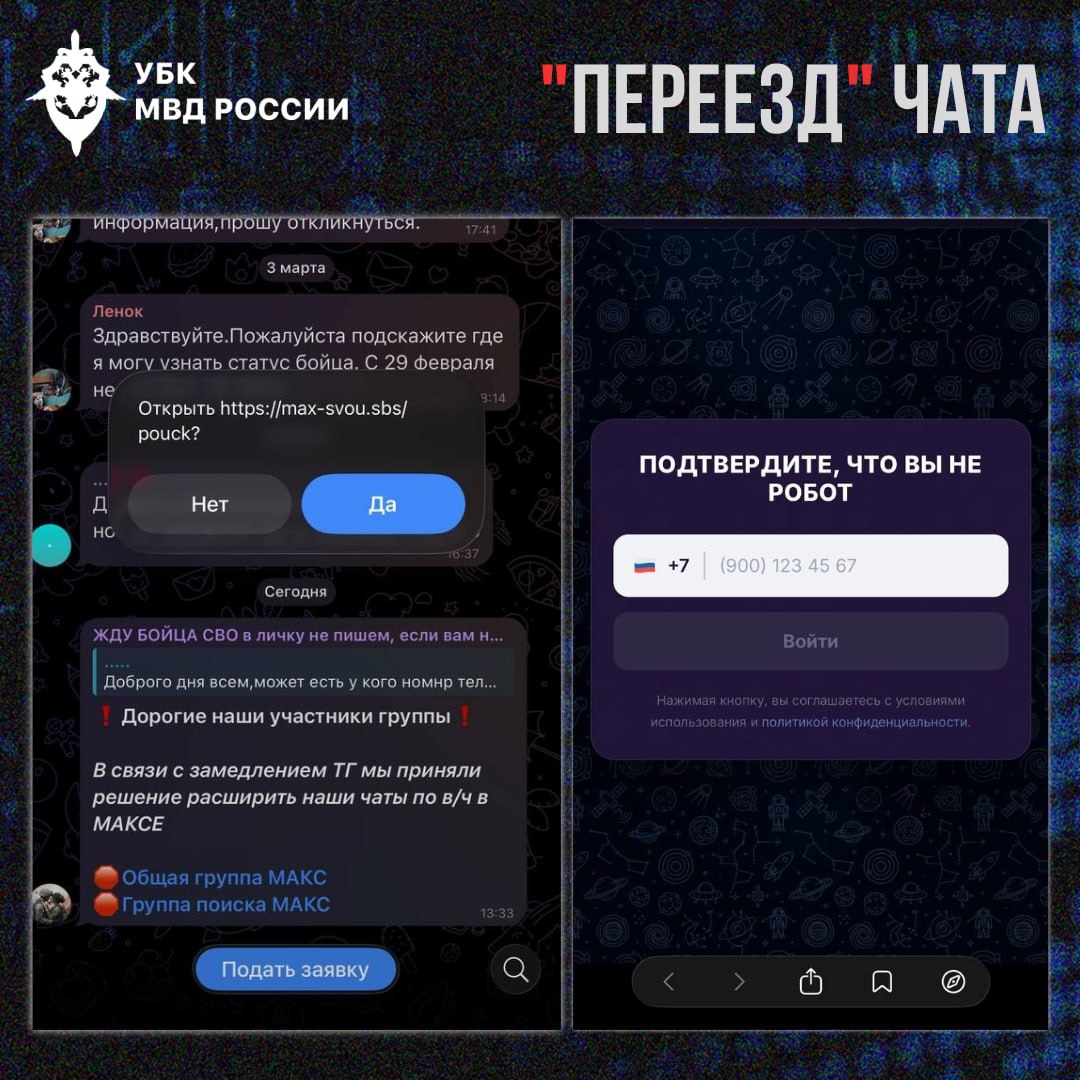
Там злоумышленники размещают сообщения о якобы переносе чата на другую платформу из-за блокировок или технических проблем.
Однако ссылка, которую публикуют мошенники, ведёт в бот. В нём пользователю предлагают ввести номер телефона и код из СМС-сообщения. Так происходит угон аккаунта уже на другой платформе.
«Подобные сообщества изначально находятся в зоне повышенного внимания противника. Размещая там персональные данные, фотографии, детали службы или перемещений, пользователи нередко сами раскрывают чувствительную информацию. Также чаты используются мошенниками для выбора жертв. После размещения сообщений о поиске злоумышленники могут выходить в личные сообщения с предложениями „помощи“, „ускорения выплат“ или „проверки статуса“», — предупреждает УБК МВД.
Массовые кампании по краже аккаунтов в МАКС фиксировались и раньше. Обычно злоумышленники действовали от имени сотрудников команды мессенджера и предлагали активировать «аккаунт безопасности». Выполнение таких инструкций приводило к потере учётной записи.
В целом активность злоумышленников на российской платформе остаётся довольно высокой. МАКС используют для распространения вредоносных приложений и фишинговых ссылок.