












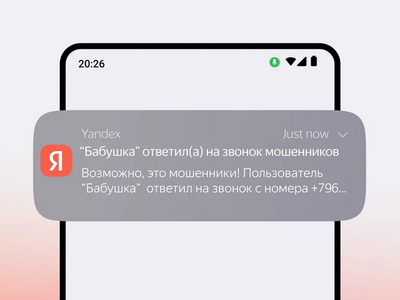
У «Яндекса» появилась новая функция в определителе номера: теперь сервис может уведомлять пользователя, если его родственникам или близким звонят с подозрительных номеров — или если они сами перезванивают мошенникам. Идея простая: если, например, пожилому человеку позвонили злоумышленники, об этом узнает кто-то из доверенных и сможет быстро вмешаться.
Причём система не ограничивается моментом звонка. Определитель продолжает анализировать номер ещё в течение суток, и если позже он «переобуется» в мошеннический, уведомление всё равно придёт.
Оповещения можно получать разными способами: через пуши в приложениях «Яндекса», по СМС или в мессенджерах. Пользователь сам выбирает, как именно ему удобнее.
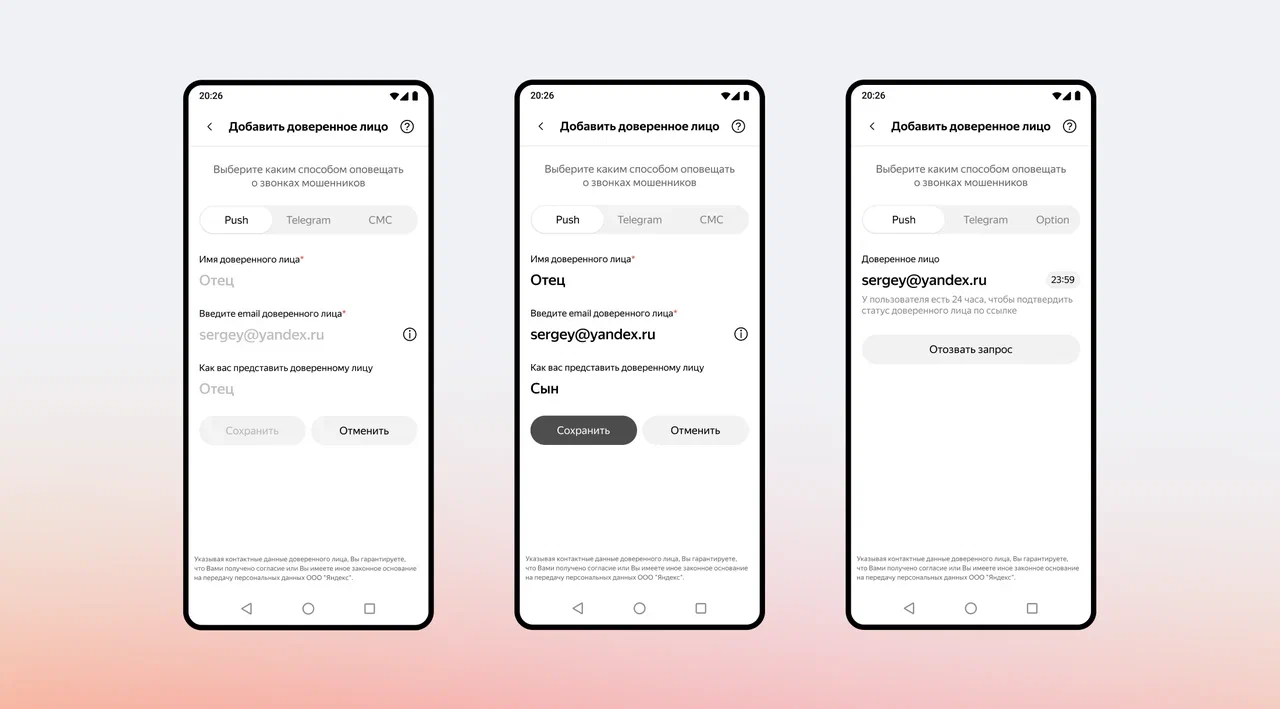
Работает это через связку доверенных лиц. Чтобы подключить функцию, нужно добавить человека, который будет получать уведомления, в настройках определителя номера. С другой стороны, этот человек должен согласиться принимать такие оповещения.
В одном аккаунте можно указать до трёх доверенных контактов. Таким образом, за одним пользователем могут присматривать сразу несколько близких и, наоборот, один человек может следить за безопасностью нескольких родственников.
Функция уже доступна в «Яндекс Браузере» и приложении «Яндекс с Алисой» на Android.



