










Security Vision начала год с нового релиза своей платформы. В обновлении разработчики сосредоточились на прикладных вещах: улучшили визуализацию данных, расширили журналирование и упростили работу с экспортом, импортом и административными настройками.
Аналитика и визуализация
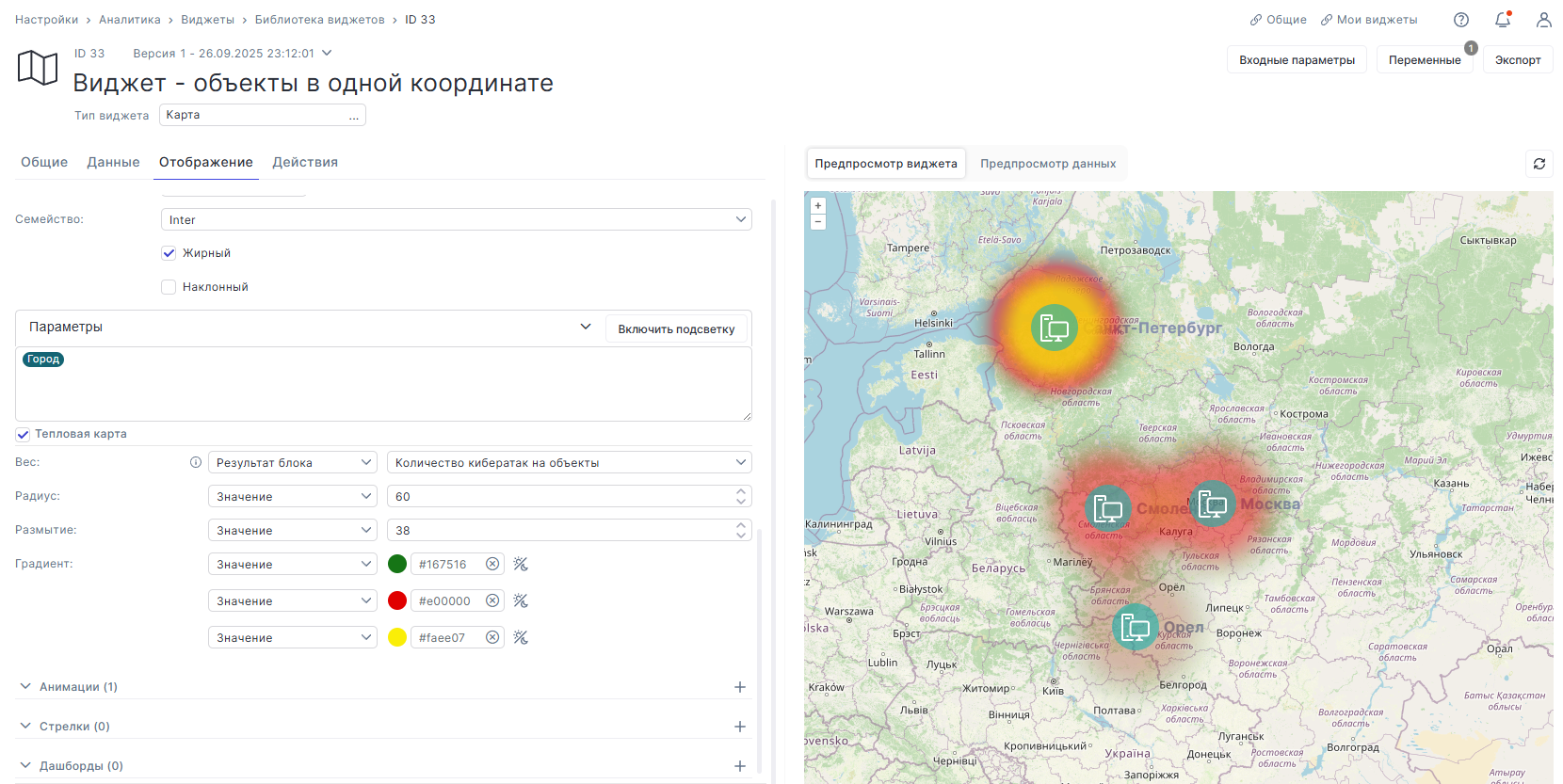
В виджете «Карта» появилась тепловая карта. Она позволяет наглядно показывать интенсивность, частоту и количество событий — например, кибератак или инцидентов — в разрезе ИТ-объектов.
В виджете «Последовательность (Timeline)» добавили настраиваемые формы отображения параметров, используемых при выводе данных. Это упрощает анализ цепочек событий и работу с временными срезами.
Журналирование и контроль действий
Журнал аудита стал подробнее. Теперь в нём фиксируются события включения и отключения коннекторов, а также расширена информация о действиях, выполняемых с сервисом коннекторов.
Кроме того, в аудит добавлены записи об остановке и удалении запущенных рабочих процессов, а также о создании отчётов, что повышает прозрачность операций и упрощает разбор спорных ситуаций.
Экспорт, импорт и администрирование
При формировании пакета экспорта теперь можно выбрать все связанные с исходной сущностью объекты только для вставки, без замены при импорте. Это особенно удобно при передаче крупных и связанных наборов данных.
В системных настройках очистки истории появилась возможность удалять записи о выполненных операциях импорта и экспорта системных сущностей, что помогает поддерживать порядок в журнале событий.
Обновления интерфейса
В релизе доработан интерфейс формы настроек журнала аудита, переработан раздел «Профиль пользователя», а также обновлены представления для внутрипортальных уведомлений.
Работа с JSON
В блоке преобразований для работы с JSON унифицированы списки вариантов в поле «Название свойства» — теперь они соответствуют вариантам выборки в поле «Значение свойства». Это касается операций добавления, объединения, удаления и поиска по JPath и XPath.
Security Vision продолжает развивать платформу, делая акцент на удобстве повседневной работы, прозрачности процессов и более наглядной аналитике.



