








Корпорация Symantec сообщает об обнаружении интернет-активности, эксплуатирующей новые уязвимости нулевого дня (CVE-2013-0640, CVE-2013-0641) в продуктах Adobe Reader и Adobe Acrobat XI и более ранних версий. Компания Adobe пока не выпустила исправления по этим уязвимостям, но опубликовала рекомендации по противодействию эксплуатирующим их атакам. Решение для защиты от вирусов на уровне почтовых серверов Symantec Mail Security обеспечивает защиту от этих атак, предотвращая загрузку вредоносных PDF-файлов.
Изначально интернет-сообщество опиралось на отчёт о новой 0-day уязвимости, опубликованный компанией FireEye. В нём сообщалось, что в результате её успешной эксплуатации на компьютер были загружены несколько файлов. Анализ экспертов Symantec подтверждает такую возможность.
Рисунок. 1. Атака посредством CVE-2013-0640
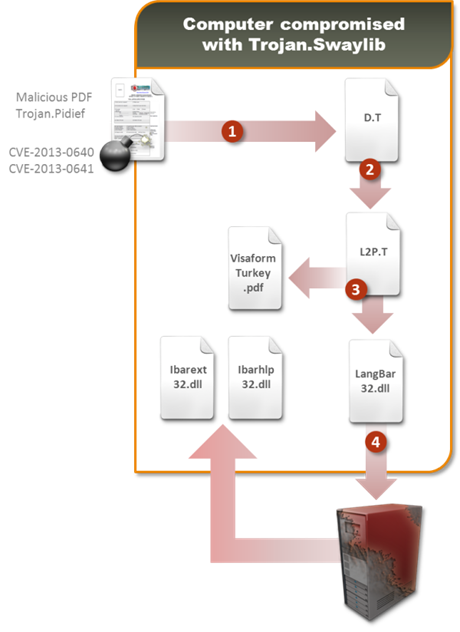
Атака, этапы которой показаны выше на рис. 1, проходит следующим образом:
- Вредоносный PDF-файл устанавливает DLL-библиотеку под названием D.T;
- D.T декодирует и устанавливает DLL-библиотеку под названием L2P.T;
- L2P.T создает в реестре ключи автозапуска и загружает на компьютер библиотеку-загрузчик LangBar32.dll;
- LangBar32.dll с сервера злоумышленников скачивает дополнительное вредоносное ПО с бэкдор- и кейлоггер-функционалом.
На этих этапах атаки продукты Symantec идентифицируют вредоносные программы как Trojan.Pidief и Trojan.Swaylib (изначально − как Trojan Horse). Помимо этого, с целью выявления данного эксплойта было выпущено дополнительное определение (сигнатура) для системы предотвращения вторжений (IPS) Web Attack: Malicious PDF File Download 5.
Дальнейшее исследование показало, что PDF-файл, примененный в атаке, нейтрализуется продуктом Symantec Mail Security, а используемые в ходе атаки PDF-файлы идентифицируются облачными технологиями детектирования Symantec как WS.Malware.2.






