















«Лаборатория Касперского» представила новый продукт Kaspersky Vulnerability Management — систему для поиска, оценки и приоритизации уязвимостей в корпоративной инфраструктуре. Презентация проходит на мероприятии компании, где находится редакция Anti-Malware.ru.
Основным спикером выступил Антон Иванов. По его словам, решение создавали по запросам клиентов: продукт должен минимально нагружать инфраструктуру, укладываться в разумную совокупную стоимость владения и работать как часть общей экосистемы вендора.

Интерес компании к этому направлению вполне объясним. Мировой рынок систем управления уязвимостями растёт примерно на 12% в год. Российский сегмент по итогам 2025 года оценивается в 8,3 млрд рублей.

В «Лаборатории Касперского» делают ставку на собственную экспертизу в исследовании угроз. За всё время специалисты компании обнаружили 32 уязвимости нулевого дня.
Само управление уязвимостями тем временем превращается из полезной функции в обязательный элемент защиты. Критических дыр становится больше, а искусственный интеллект ускоряет не только работу защитников, но и поиск способов атаковать системы.

В компании описывают происходящее формулой: 0-day превращается в 0-hour. Иными словами, времени между обнаружением уязвимости и её реальной эксплуатацией становится всё меньше.
Как и у других решений этого класса, центральной функцией Kaspersky Vulnerability Management станет скоринг и приоритизация. Представители компании в ответ на вопросы генерального директора Anti-Malware.ru Ильи Шабанова уточнили, что в следующем релизе планируют добавить кастомный скоринг с учётом контекста уязвимого актива.
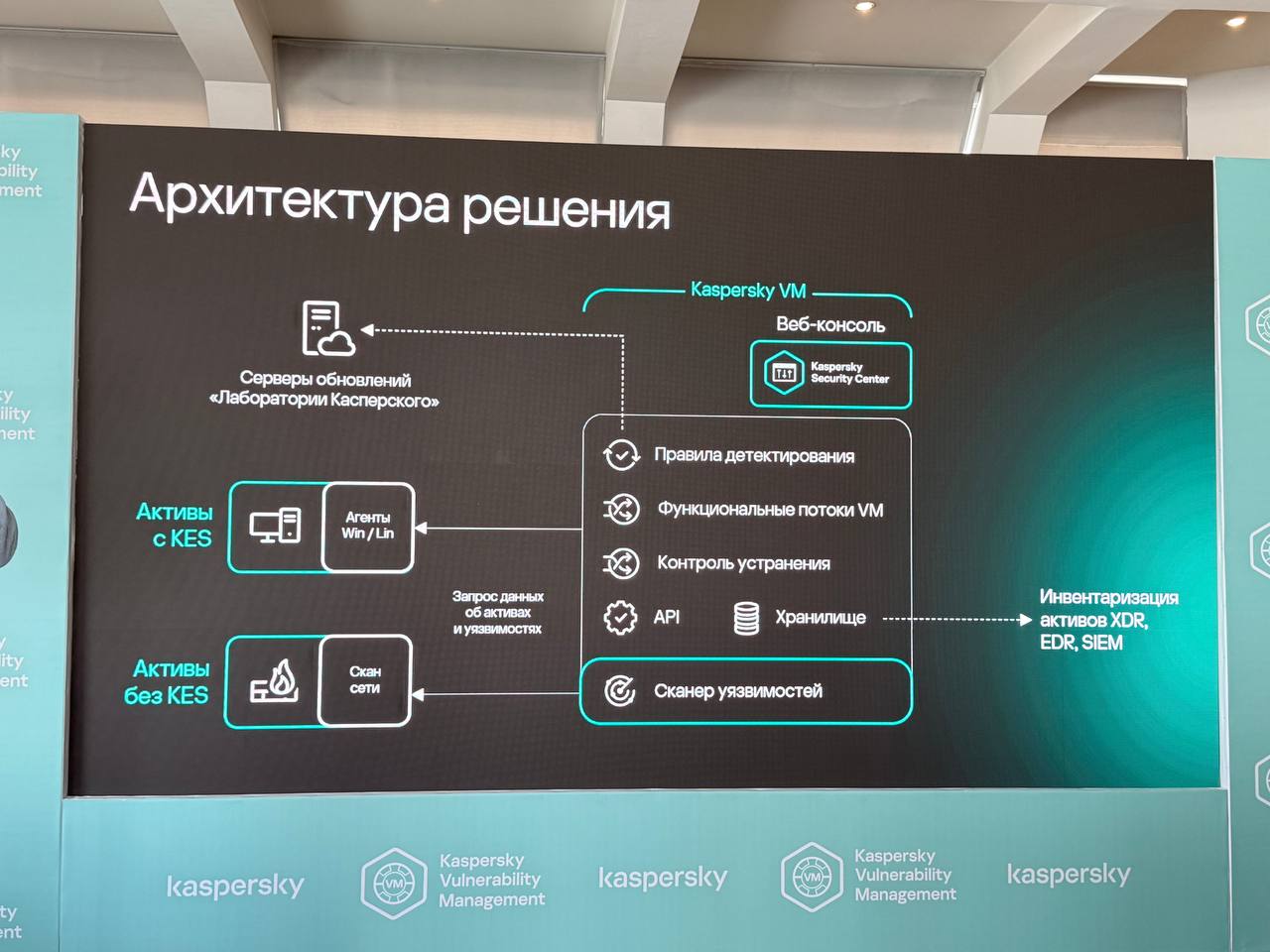
Быстродействие и низкую нагрузку на инфраструктуру разработчики собираются обеспечить за счёт переиспользования Kaspersky Endpoint Security на хостах и оптимизированного безагентского сканирования.



