Команда DeepSeek представила новый модуль Engram, который добавляет в трансформеры то, чего им давно не хватало, — встроенную память для быстрого извлечения знаний. Идея проста, но эффектная: вместо того чтобы снова и снова пересчитывать одни и те же локальные паттерны, модель может мгновенно «вспоминать» их через O(1)-lookup и тратить вычисления на более сложные задачи — рассуждения и дальние зависимости.
Engram работает не вместо Mixture-of-Experts (MoE), а вместе с ним. Если MoE отвечает за условные вычисления, то Engram добавляет вторую ось масштабирования — условную память.
По сути, это современная версия классических N-грамм, переосмысленная как параметрическая память, которая хранит устойчивые шаблоны: частые фразы, сущности и другие «статичные» знания.
Технически Engram подключается напрямую к трансформерному бэкбону DeepSeek. Он построен на хешированных таблицах N-грамм с мультихед-хешированием, лёгкой свёрткой по контексту и контекстно-зависимым гейтингом, который решает, сколько памяти «подмешать» в каждую ветку вычислений. Всё это аккуратно встраивается в существующую архитектуру без её радикальной переделки.
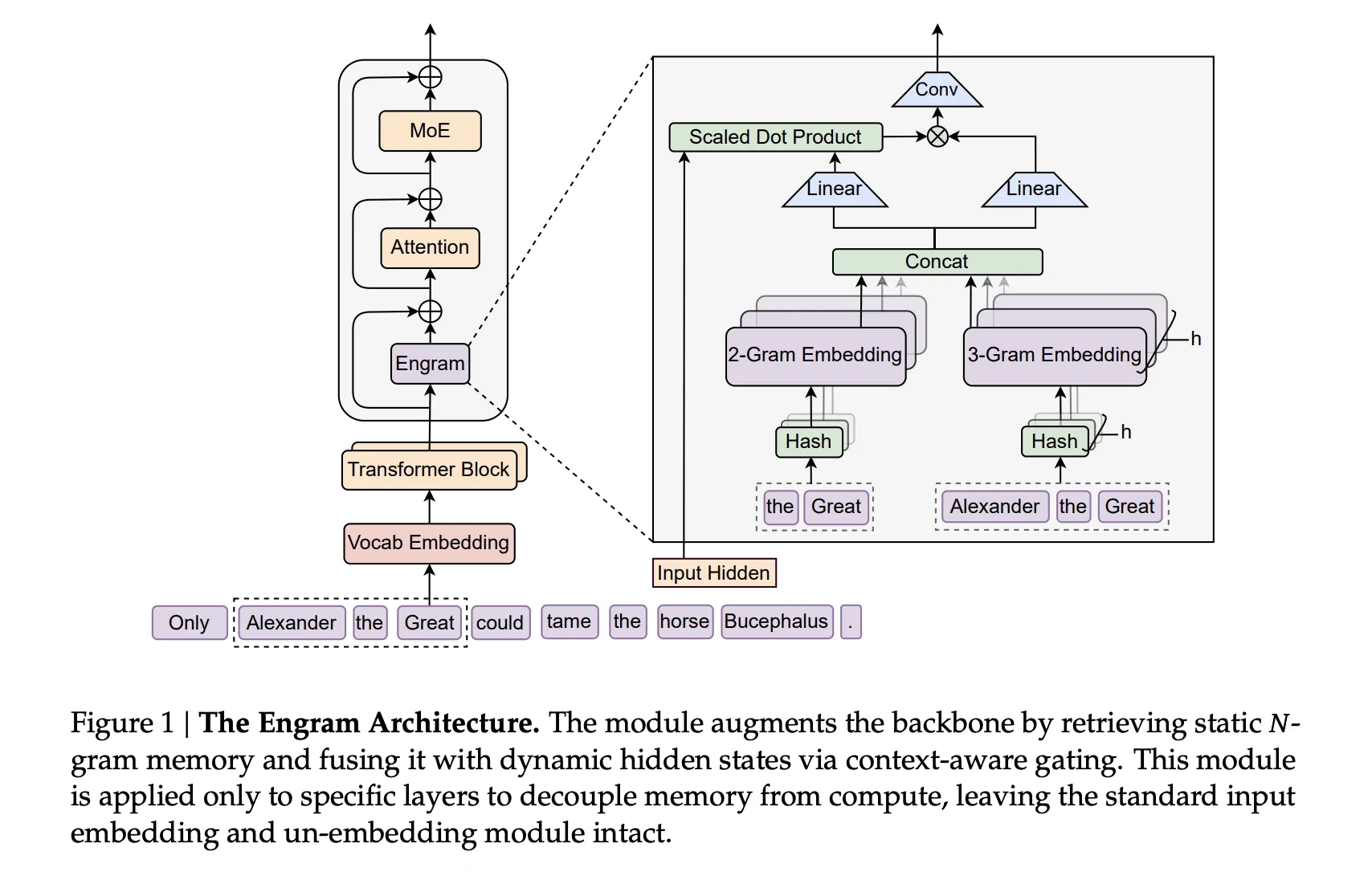
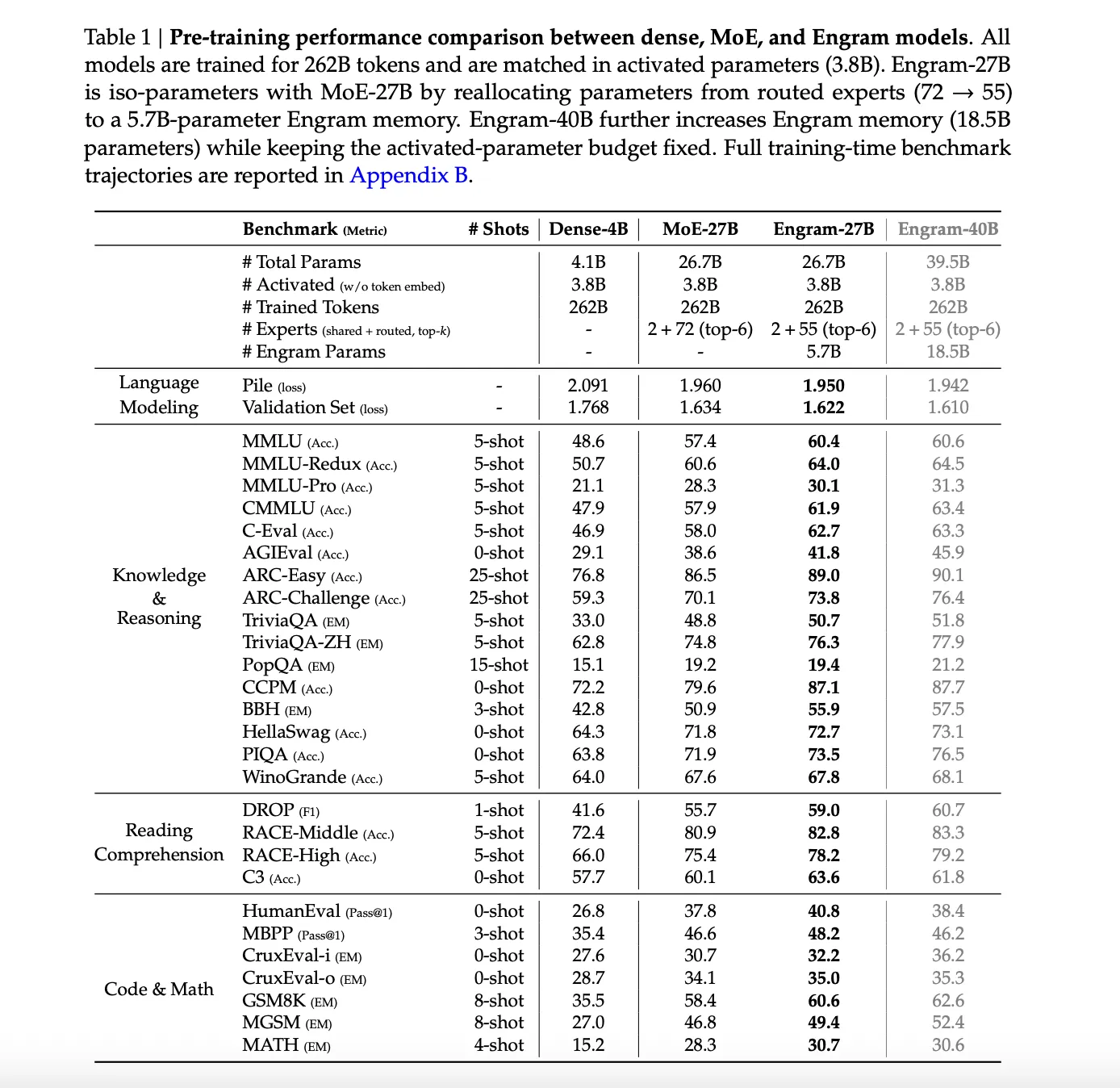
На больших моделях DeepSeek пошла ещё дальше. В версиях Engram-27B и Engram-40B используется тот же трансформерный бэкбон, что и у MoE-27B, но часть параметров перераспределяется: меньше маршрутизируемых экспертов — больше памяти Engram. В результате Engram-27B получает около 5,7 млрд параметров памяти, а Engram-40B — уже 18,5 млрд, при этом число активируемых параметров и FLOPs остаётся тем же.
Результаты предобучения на 262 млрд токенов выглядят убедительно. При одинаковом числе активных параметров Engram-модели уверенно обходят MoE-базу: снижается задержка, растут показатели на задачах знаний и рассуждений. Например, MMLU увеличивается с 57,4 до 60,4, ARC Challenge — с 70,1 до 73,8, BBH — с 50,9 до 55,9. Улучшения есть и в коде, и в математике — от HumanEval до GSM8K.
Отдельно исследователи посмотрели на длинный контекст. После расширения окна до 32 768 токенов с помощью YaRN Engram-27B либо сравнивается с MoE-27B, либо превосходит его Причём иногда Engram достигает этого при меньших вычислительных затратах.
Механистический анализ тоже говорит в пользу памяти. Варианты с Engram формируют «готовые к предсказанию» представления уже на ранних слоях, а по CKA видно, что неглубокие слои Engram соответствуют гораздо более глубоким слоям MoE. Проще говоря, часть «глубины» модель получает бесплатно, выгружая рутину в память.
Авторы подытоживают: Engram и MoE не конкурируют, а дополняют друг друга. Условные вычисления хорошо справляются с динамикой и рассуждениями, а условная память — с повторяющимися знаниями. Вместе они дают более эффективное использование параметров и вычислений без ломки архитектуры.



















