








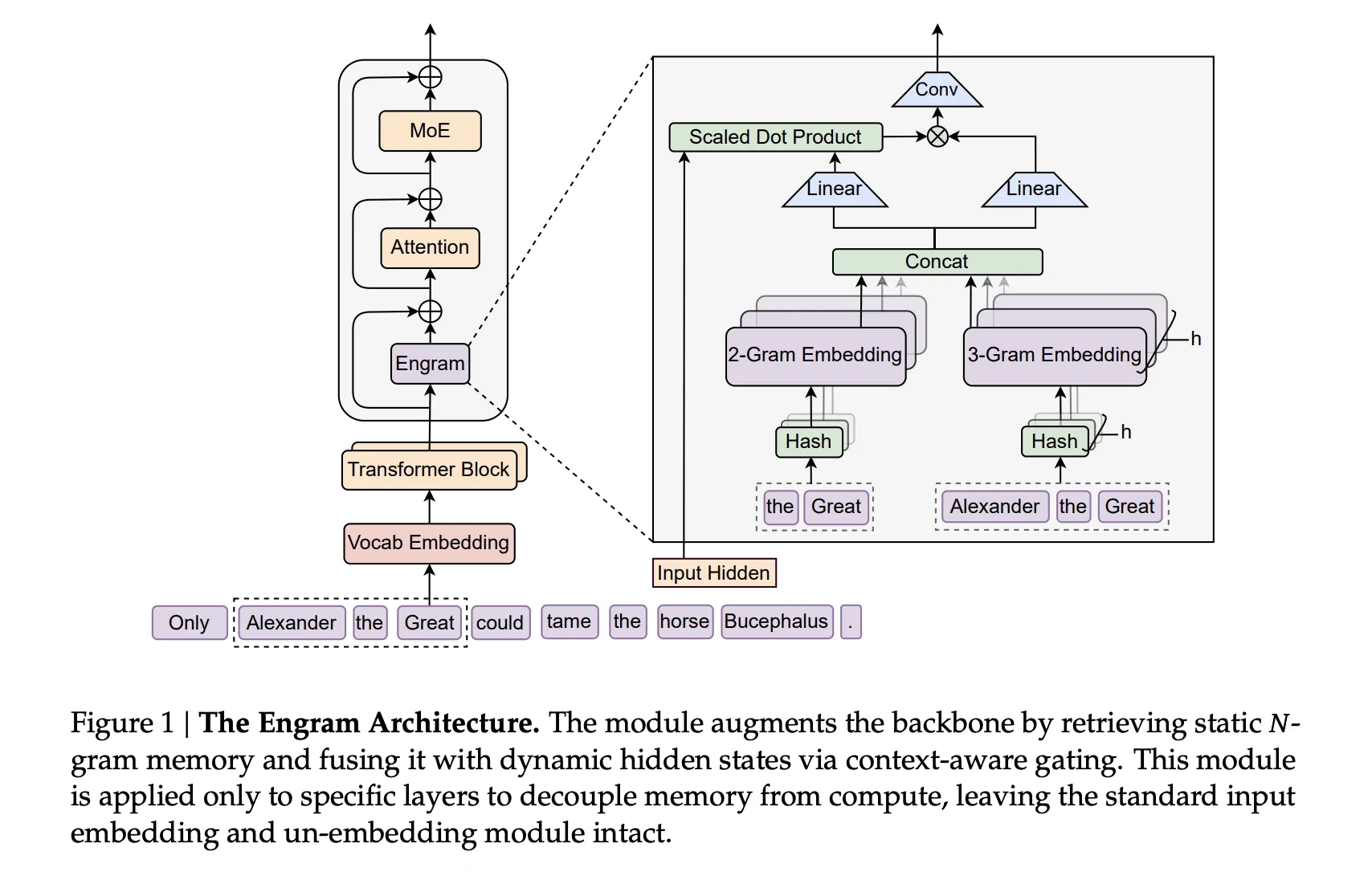







Мошенники создали фейковые сайты Минобороны и предложили родственникам погибших участников СВО зарегистрироваться для получения государственных наград. Вместо приглашения на церемонию посетителей ждала охота за персональными данными.
Поддельные страницы маскировались под официальный ресурс ведомства. Один из адресов — mil-ru-gov[.]info — похож на настоящий домен mil.ru.
Для убедительности злоумышленники добавили логотип, герб и меню, причём почти все ссылки вели на реальные страницы Минобороны. Такая декорация должна была усыпить бдительность: кругом официальные разделы, а мошенническая — только форма регистрации.
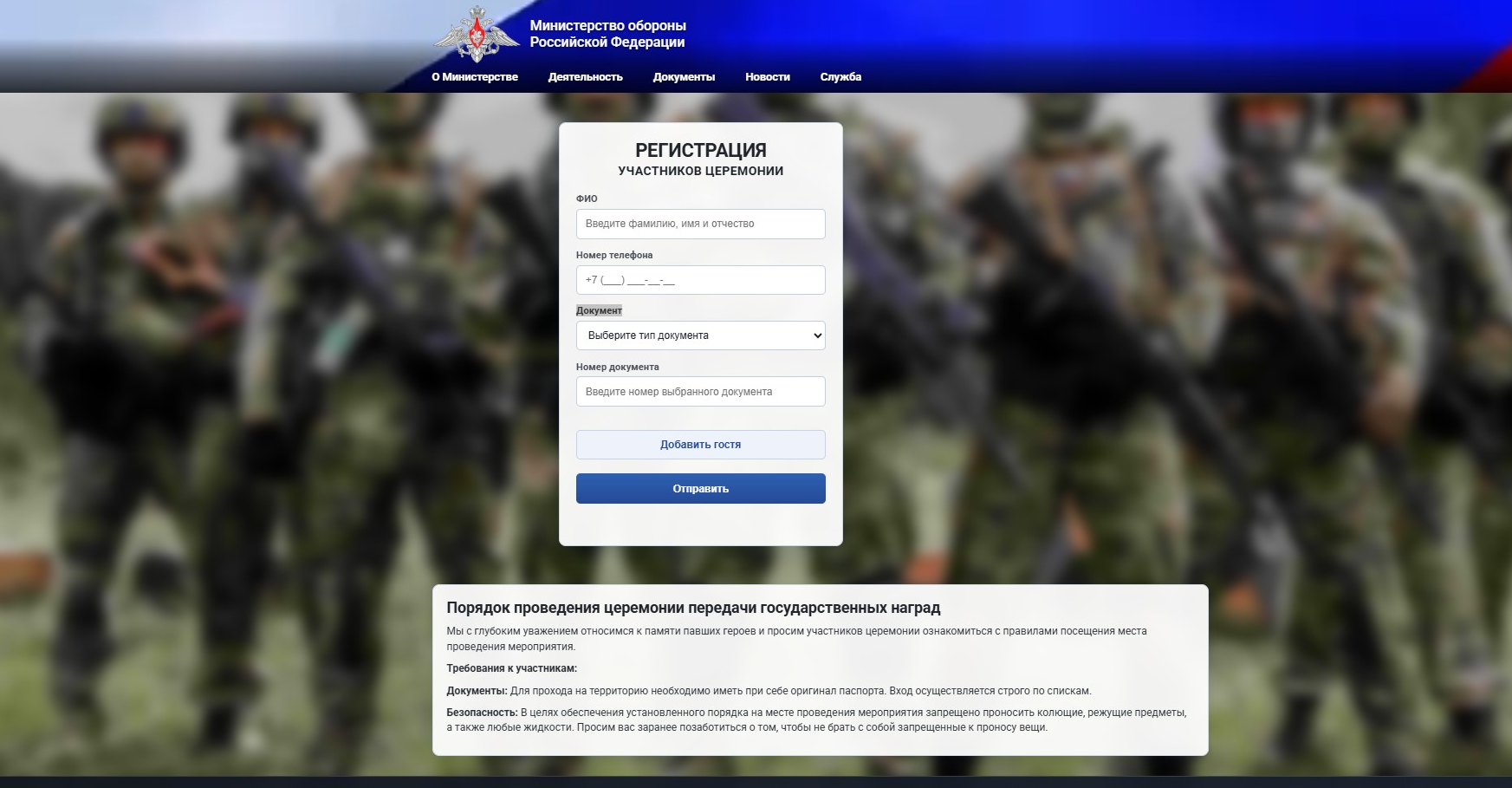
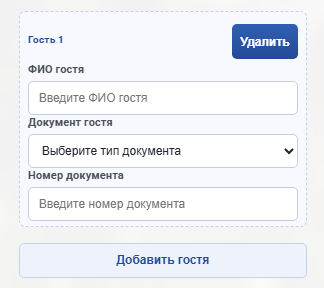
Посетителям предлагали указать ФИО, телефон и номер паспорта, СНИЛС или ИНН. На этом аппетит преступников не заканчивался: кнопка «Добавить гостя» позволяла заодно собрать сведения о сопровождающих.
Полученные данные могут использовать для восстановления доступа к госсервисам, оформления микрозаймов и дальнейших атак. Зная ФИО и телефон родственника военнослужащего, мошенники способны разыграть историю со взломом аккаунта, выманить дополнительные сведения или добраться до банковских приложений.
В «Эфшесть/F6» считают, что сайты, вероятно, создавались при помощи языковой модели. Разработчиков выдала торчащая из формы ошибка с упоминанием JSON — код собрали на скорую руку и даже не удосужились подчистить. Впрочем, краже данных она не мешала: сообщение появлялось уже после их отправки на сервер злоумышленников.
Как распространялись ссылки, пока неизвестно. Их могли рассылать адресно через мессенджеры и электронную почту. Обнаруженные сайты уже заблокированы в России, но мошенникам ничто не мешает завести новые домены. Цинизма у этой схемы с запасом, а регистрационная форма собирает ровно то, что добровольно отдавать нельзя.



