













Apple продолжает прокачивать не только интерфейс iOS 27, но и фирменные приложения. Одно из самых заметных обновлений досталось сервису Локатор (Find My), который получил новые настройки приватности и переработанный дизайн. Главная фишка — возможность незаметно скрывать своё местоположение от конкретного человека.
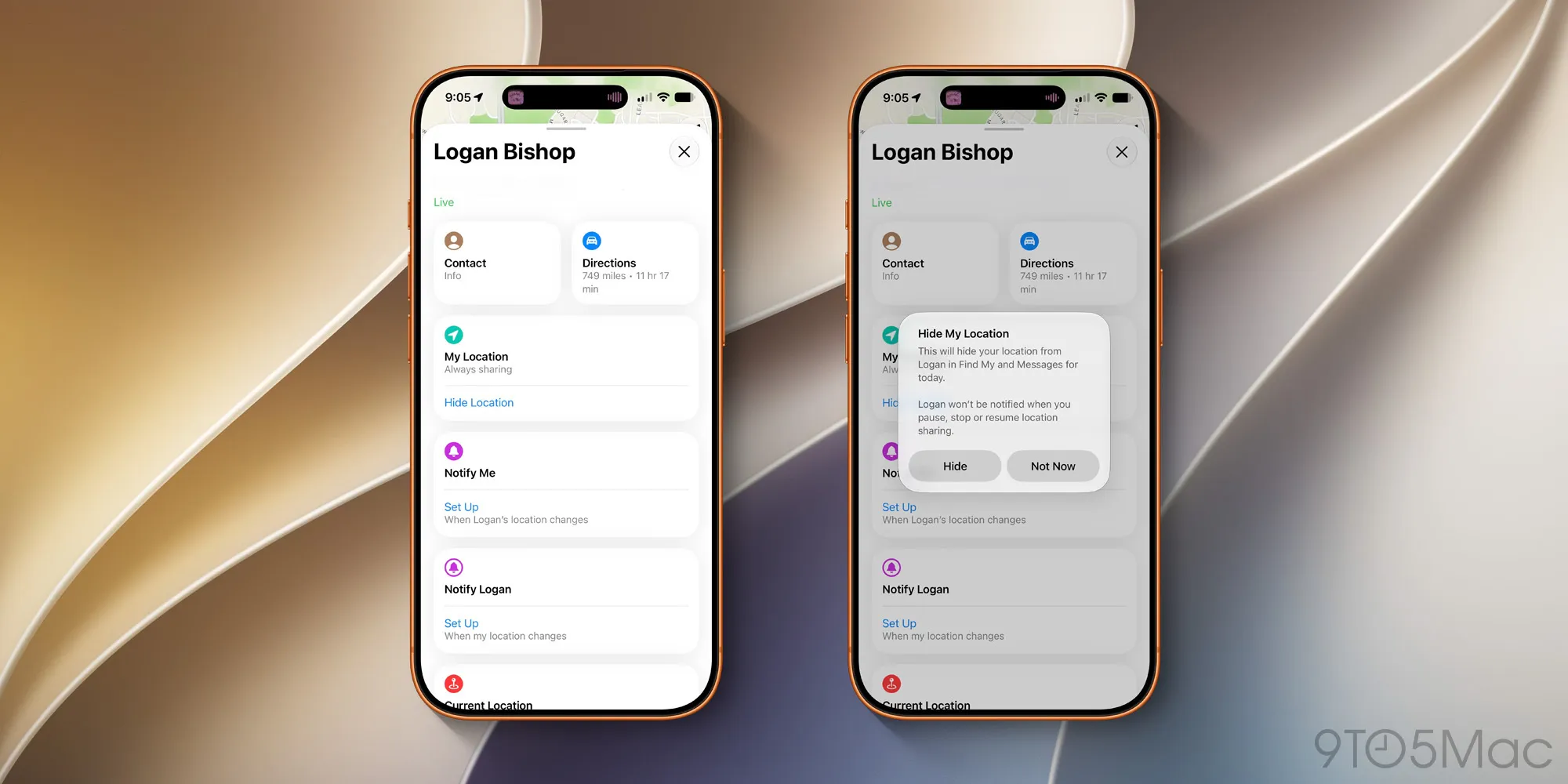
Теперь в карточке каждого контакта появился отдельный переключатель «Скрыть местоположение».
Его можно активировать в любой момент, а другой пользователь при этом не получит никаких уведомлений о том, что доступ к вашему местоположению исчез.
Вместо этого в приложении у него просто появится сообщение «Местоположение не найдено». Причём Apple не станет сообщать и о последующем возобновлении передачи геоданных. Получается своеобразный режим невидимки для избранных контактов.
Источник: 9to5mac
Заодно компания добавила более гибкие настройки обмена геолокацией. Теперь можно заранее указать точное время или дату, до которых будет действовать доступ к геопозиции. После этого передача координат отключится автоматически.
Не обошлось и без визуальных изменений. Локатор наконец получил элементы нового интерфейса Liquid Glass, который Apple активно внедряет по всей системе. В приложении появился обновлённый дизайн панели вкладок, а на главном экране теперь отображается больше информации о местоположении людей без необходимости открывать их карточки.
Например, если раньше для просмотра точного адреса приходилось нажимать на контакт, то теперь приложение может сразу показать улицу, на которой находится человек.
Также Apple слегка освежила набор иконок. Вкладка с отслеживаемыми предметами получила новый значок в стиле AirTag.
На первый взгляд обновление выглядит косметическим, но функция скрытия местоположения без уведомлений вполне может стать одной из самых обсуждаемых возможностей iOS 27. Особенно среди тех, кто привык делиться геолокацией с друзьями, родственниками или второй половиной.



