














Операторы банковского трояна Astaroth научили заражённые компьютеры самостоятельно рассылать вредоносные архивы через WhatsApp Web (принадлежит корпорации Meta, признанной экстремистской и запрещённой в России). Теперь жертва не только рискует банковскими данными, но и невольно подбрасывает троян своим контактам, выяснили специалисты CrowdStrike.
Раньше Astaroth, также известный как Guildma, в основном распространялся через фишинговые письма. В конце 2025 года преступники прикрутили к нему отдельный спам-бот для WhatsApp.
Модуль копирует профиль Chrome или Edge, загружает официальный WebDriver и запускает браузер в фоновом режиме. Затем он подключается к уже авторизованной сессии WhatsApp Web при помощи легитимной библиотеки WPPConnect/WA-JS. Для пользователя всё выглядит тихо, а за кулисами начинается обход адресной книги.
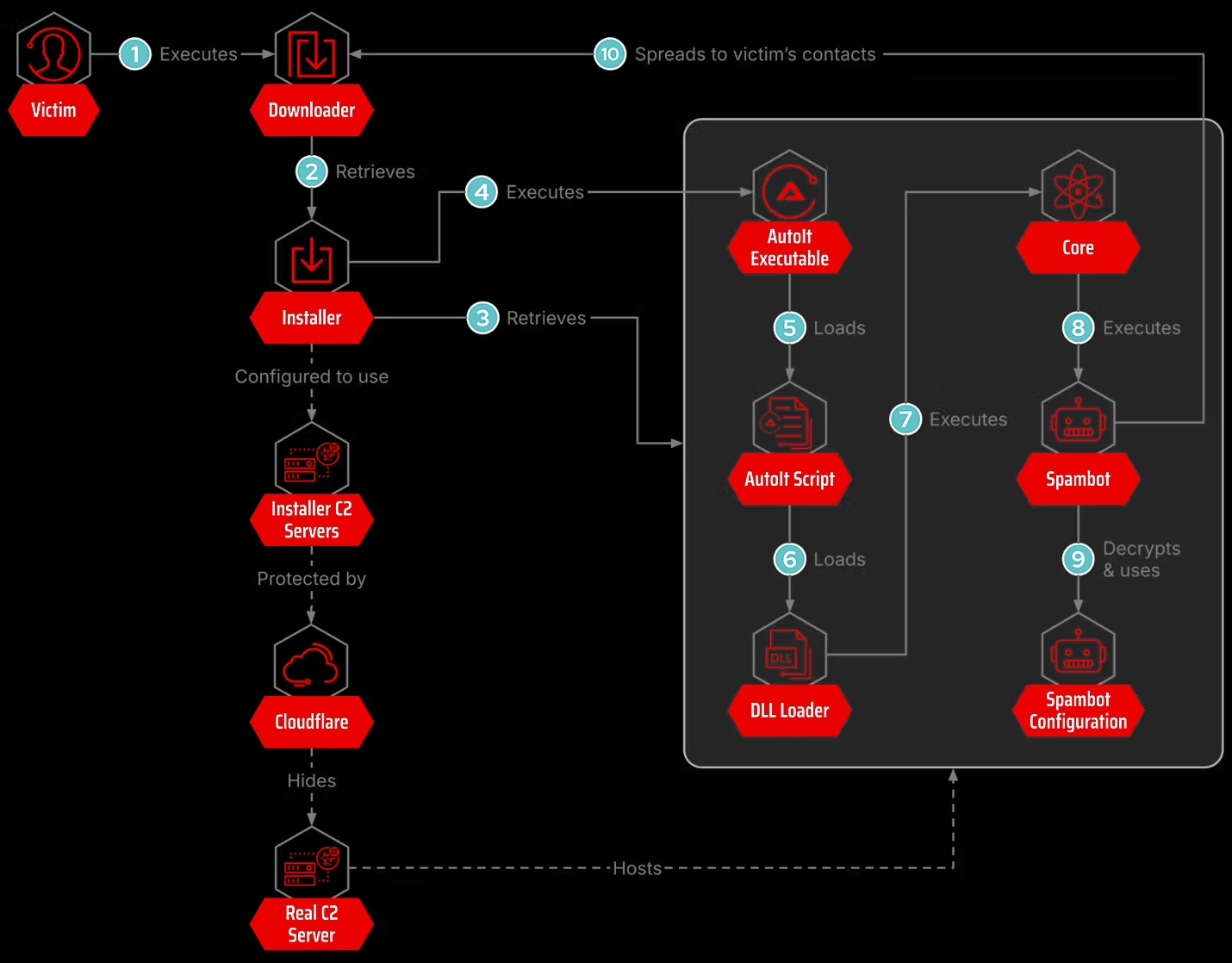
Каждому контакту бот отправляет три сообщения: приветствие с учётом времени суток, ZIP-архив с загрузчиком Astaroth и заключительный текст. Ссылки и формулировки выбираются случайно, чтобы рассылка не выглядела клонированной и хуже ловилась защитными системами.
В итоге вредонос приходит не от подозрительного незнакомца, а от знакомого человека. Расчёт простой: сообщениям из собственной адресной книги доверяют охотнее, особенно если они написаны естественно и начинаются с уместного «доброе утро».
Код спам-бота похож на инструменты других латиноамериканских группировок, включая Vareg. Совпадения в настройках, функциях и логике фильтрации указывают на общего разработчика или активный обмен наработками внутри местного киберпреступного рынка.
Признаками заражения могут быть загрузка WebDriver через PowerShell, папки ChromeAuto_ в C:\Users\Public\Temp, запуск Chromium в безголовом режиме и обращения к компонентам WPPConnect. Astaroth фактически заставил WhatsApp работать курьером для банковского трояна, причём посылку оплачивает сама жертва.



