







Большинство заходящих на торрент-ресурс The Pirate Bay пользователей скачивают свежий контент, однако среди раздач есть, без преувеличения, старожилы, которым уже стукнуло 20 лет.
Издание TorrentFreak приводит интересную статистику: один из эпизодов шведского сериала «Высокий кустарник» раздаётся на «Пиратской бухте» уже более 20 лет. Этот же юбилей отметил документальный фильм об истории GNU, Linux — «Revolution OS».
Сама площадка The Pirate Bay, напомним, стартовала в 2003 году, когда ещё интернет не знал, что такое YouTube, Facebook и прочие. Napster в то время предлагал людям бесплатную музыку, а вот «Пиратская бухта» пошла дальше, добавив другие типы медиаконтента — сериалы и фильмы.
Большинство старых торрент файлов на сегодняшний день, конечно же, недоступны. Протокол BitTorrent требует хотя бы одного раздающего полной копии файла, чтобы сама раздача была активной. Некоторым, судя по всему, удаётся раздавать десятилетиями.
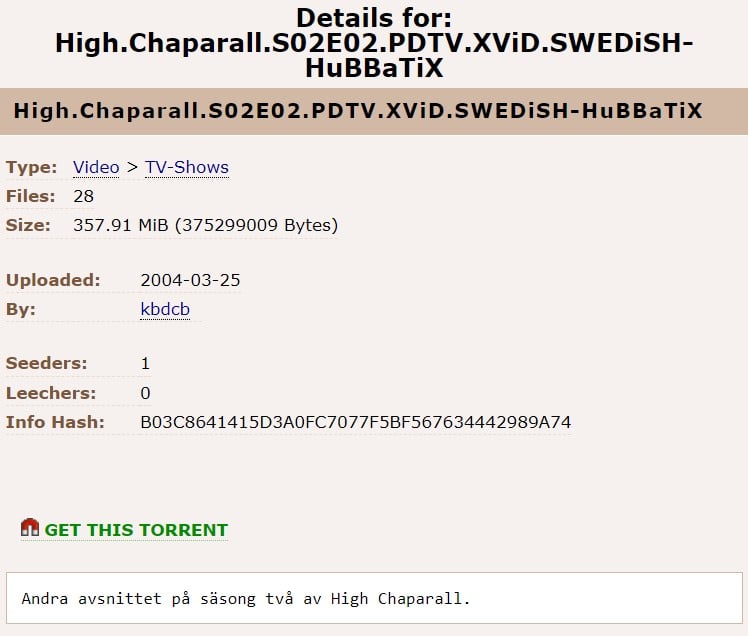
Например, несколько дней назад 20 лет исполнилось торрент-файлу одного из эпиздоров сериала «Высокий кустарник». Его опубликовали 25 марта 2004 года.
Документалка «Revolution OS» также может похвастаться долгожительством: соответствующую раздачу запустили 31 марта 2004 года.



