







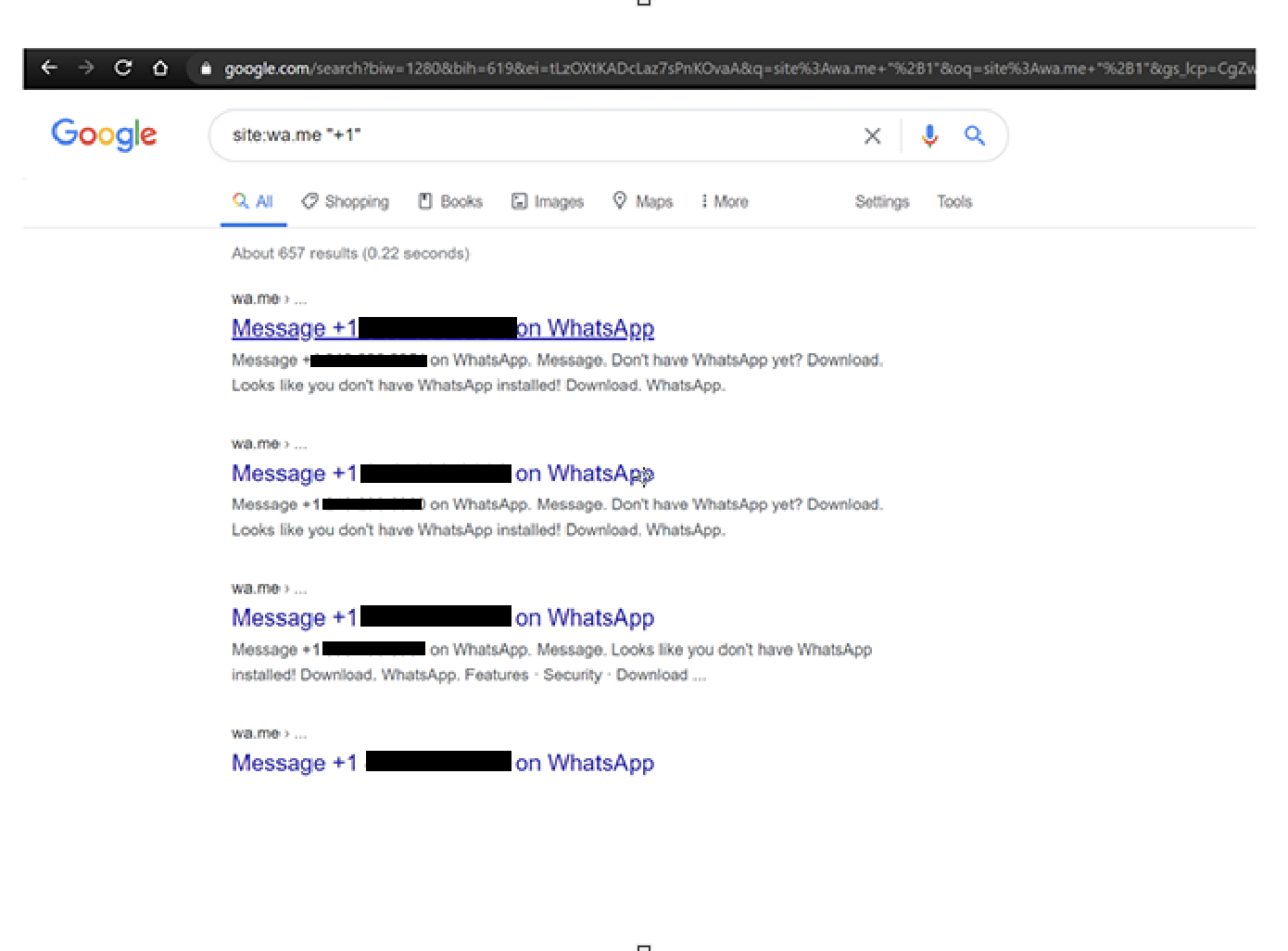
Исследователь в области безопасности обнаружил ряд телефонных номеров, привязанных к аккаунтам WhatsApp, в открытом доступе. Оказалось, что поисковой движок Google проиндексировал их, в связи с чем эксперт объявил это проблемой конфиденциальности.
Специалист ссылается на функцию под названием «Click to Chat», поскольку именно она позволяет поисковой системе Google Search индексировать телефонные номера пользователей.
Однако представители Facebook утверждают, что это абсолютно нормальная ситуация — поисковик индексирует лишь то, что люди сами предпочли сделать общедоступным.
С такой позицией несогласен Атул Джейрем, занимающийся поиском уязвимостей и других проблем безопасности. Он называет появление телефонов в поисковой выдаче «утечкой» и считает, что в WhatsApp присутствует баг, угрожающий конфиденциальности пользователей.
Давайте разберёмся, что же собой представляет «Click to Chat». На самом деле, эта функция может быть действительно полезна, поскольку позволяет веб-сайтам общаться с посетителями через WhatsApp.
Для этого используется специальный QR-код, связанный с телефонным номером владельца или администратора веб-ресурса. Зашедший на сайт пользователь может просканировать этот код, а затем кликнуть ссылку, которая запустит сессию в WhatsApp.
Джейрем видит проблему в том, что телефонные номера пользователей могут всплывать в поисковой выдаче Google, поскольку движки таких систем сканируют метаданные Click to Chat. При этом сами номера телефонов являются частью строки URL — https://wa.me/<телефонный_номер>.
В результате, как утверждает исследователь, происходит утечка телефонных номеров в виде простого текста, что позволит спамерам собрать их и использовать в своих кампаниях.
Баг или фича? Представители Threatpost связались с отдельными пользователями, чьи телефоны доступны в Сети. В большинстве случаев люди были в курсе так называемой «утечки» и даже специально использовали ситуацию для продвижения своего бизнеса или услуг.






