













Переустановка Windows наконец может стать чуть меньше похожей на танцы с бубном. Microsoft представила функцию Cloud rebuild, которая должна переустанавливать не только саму Windows, но и драйверы устройства через Windows Update.
Идея такая: пользователь сбрасывает компьютер, а система подтягивает целевой образ Windows и нужные драйверы из облака.
Сейчас свежая установка Windows часто превращается в отдельный вид страдания. Нужно понять, каких драйверов не хватает, где их скачать, что поставить первым, а что лучше вообще не трогать. Особенно весело становится, если в игру вступают видеодрайверы NVIDIA, которые умеют подарить пользователю вечер неожиданных приключений.
Cloud rebuild пока доступна участникам программы Windows Insider, начиная с Experimental Preview Build 26300.8772. В Microsoft планируют постепенно вывести функцию на более широкую аудиторию в ближайшие месяцы, если планы не изменятся.
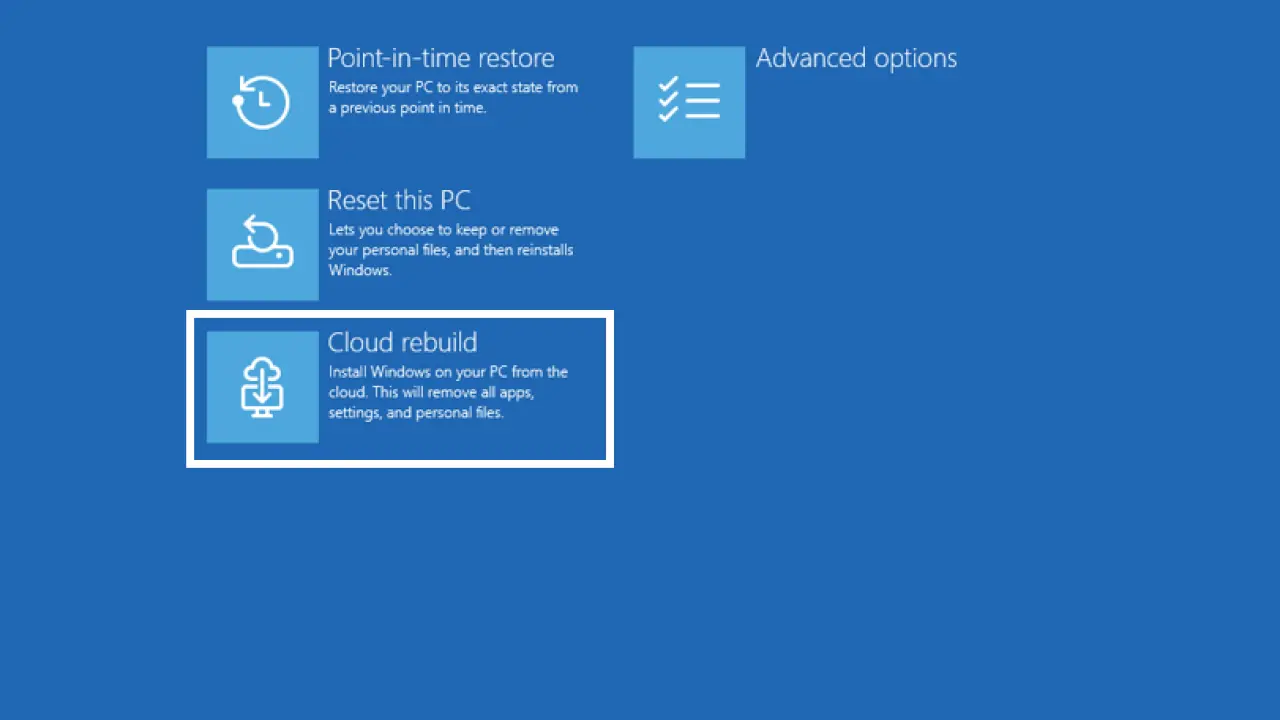
Запустить новый режим можно из среды восстановления Windows. Для этого нужно открыть WinRE, выбрать Troubleshoot → Recovery and uninstall → Cloud rebuild, подключиться к интернету по Ethernet или Wi-Fi, проверить версию, редакцию и язык Windows, а затем подтвердить предупреждение о потере данных.
Полностью все проблемы функция, конечно, не решает. Для Cloud rebuild всё равно нужен интернет, но если подключение есть, пользователю больше не придётся вручную охотиться за каждым драйвером и надеяться, что после установки система не устроит сюрприз.
Участники Windows Insider уже могут попробовать Cloud rebuild и отправить отзывы через Feedback Hub. Если всё сработает как задумано, переустановка Windows станет наконец не наказанием, а просто технической процедурой.



