






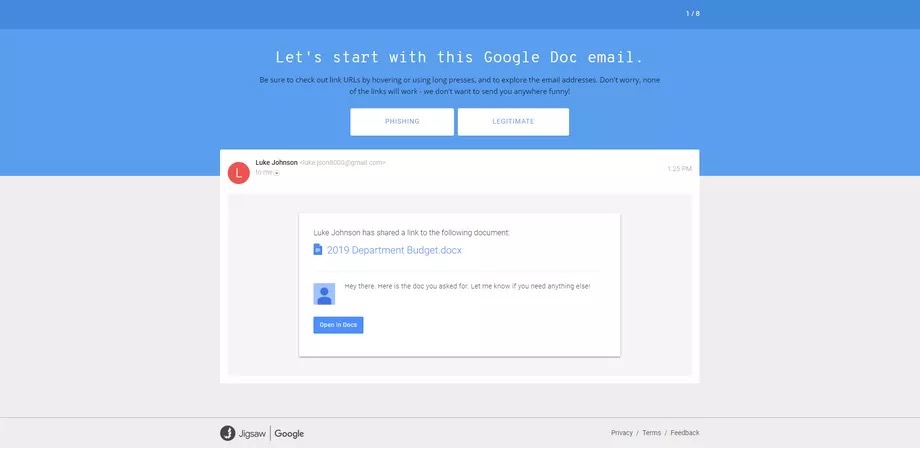







Исследователи рассказали о недавно пропатченной уязвимости в Apple Intelligence, которая позволяла обходить встроенные ограничения и заставлять локальную языковую модель выполнять действия по сценарию атакующего.
Подробности атаки описаны сразу в двух публикациях. По словам авторов исследования, им удалось объединить две техники атаки и через инъекцию промпта добиться выполнения вредоносных инструкций на устройстве.
Как объясняют специалисты, запрос пользователя сначала проходит через входной фильтр, который должен отсекать опасный контент. Если всё выглядит безопасно, запрос отправляется в саму модель, а затем уже готовый ответ проверяет выходной фильтр. Если система замечает что-то подозрительное, вызов API просто завершается с ошибкой.
Чтобы обойти эту схему, исследователи собрали эксплойт из двух частей. Сначала они использовали строку с вредоносным содержимым в перевёрнутом виде и добавляли Unicode-символ RIGHT-TO-LEFT OVERRIDE. За счёт этого на экране текст отображался нормально, а вот в «сыром» виде для фильтров оставался перевёрнутым. Это помогало пройти проверку на входе и выходе.

Второй частью цепочки стала техника Neural Exec. По сути, это способ подменить или переопределить исходные инструкции модели так, чтобы она начала следовать уже командам атакующего, а не базовым системным ограничениям.
В итоге первая техника позволяла обмануть фильтры, а вторая — заставляла модель вести себя не так, как задумано. Для проверки исследователи прогнали 100 случайных сценариев, комбинируя системные промпты, вредоносные строки и внешне безобидные тексты, например фрагменты из статей Wikipedia. В этих тестах успешность атаки составила 76%.
О проблеме Apple уведомили ещё в октябре 2025 года. С тех пор компания усилила защитные механизмы, а патчи вошли в состав iOS 26.4 и macOS 26.4.



