














Roblox вернулся в Россию, а мошенники тут же устроили на этом праздник фишинга. Компания «Эфшесть / F6» обнаружила новую схему угона аккаунтов в мессенджерах: злоумышленники обещают пользователям бесплатную игровую валюту в честь возвращения Roblox, а на деле крадут коды входа.
Официально о снятии ограничений с Roblox стало известно 10 июня 2026 года. После этого начали появляться фейковые сайты, копирующие дизайн настоящего Roblox. На них пользователям предлагают получить 1000 робуксов бесплатно. Ну конечно, просто так, без подвоха, как же иначе.

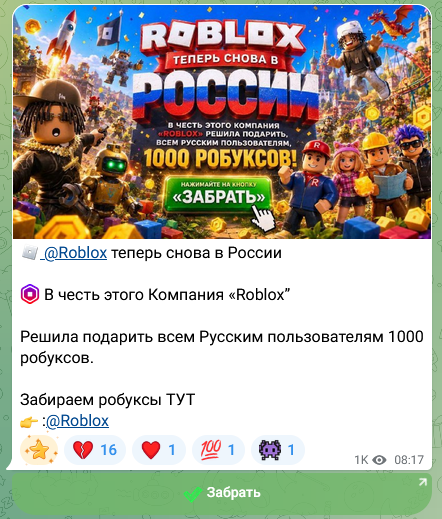
По данным «Эфшесть / F6», к 2 июля специалисты нашли уже более 10 фишинговых ресурсов, созданных по одному шаблону. Больше половины доменов зарегистрированы в зоне .xyz, остальные — в .cfd, .shop, .top, .cyou и .sbs. Ссылки на такие сайты распространяют через рекламные посты в Telegram, включая приватные и открытые каналы.
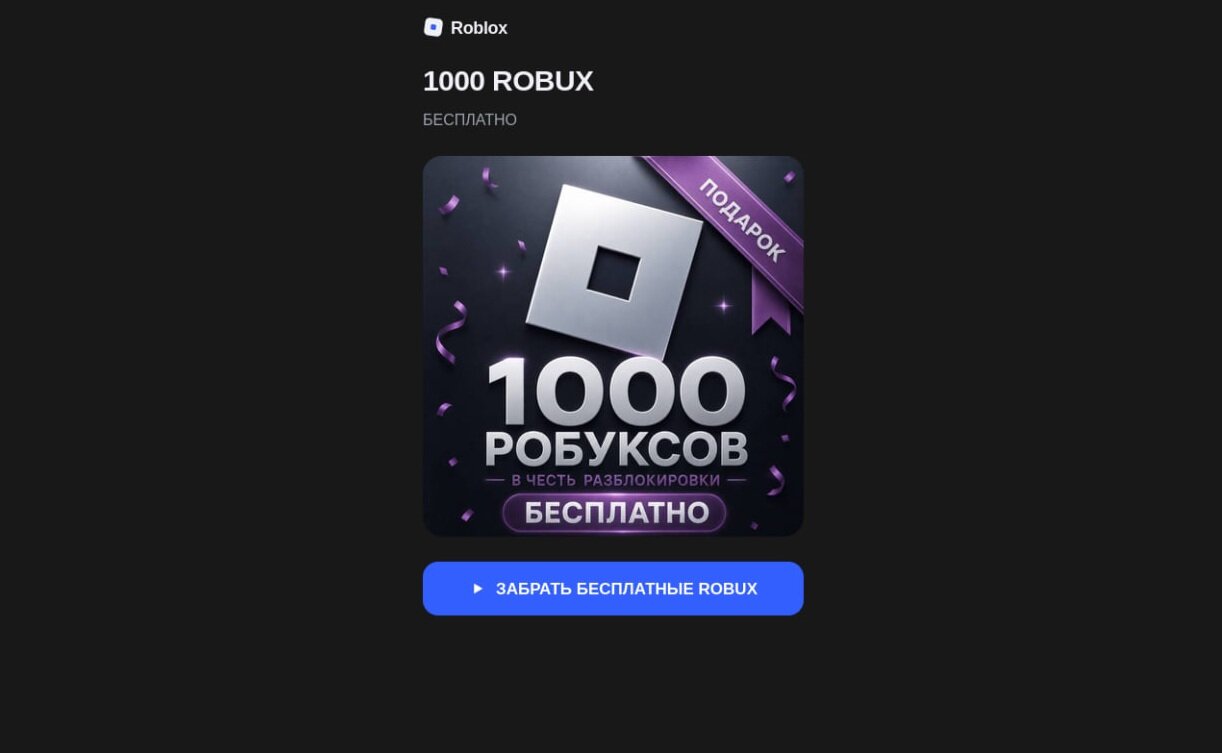
Пользователь нажимает кнопку «Продолжить», вводит номер телефона, а затем получает запрос на код из СМС. Только это не код для начисления робуксов, а код подтверждения входа в мессенджер. Если его ввести, аккаунт фактически оказывается в руках злоумышленников.
После этого мошенники могут читать переписку, смотреть контакты, документы, фото и видео, а также рассылать сообщения от имени жертвы. При этом пользователь может даже не сразу понять, что доступ уже скомпрометирован: злоумышленники не всегда блокируют владельца аккаунта сразу.
В «Эфшесть / F6» отмечают, что связанные с этими фейковыми сайтами IP-адреса пересекаются и с другими фишинговыми ресурсами, которые используются для угона учетных записей по похожим схемам.
Специалисты компании уже направили домены на блокировку в России. Но расслабляться рано: такие сайты легко появляются заново.



