













Эксперты зафиксировали новую и довольно изощрённую фишинговую кампанию в Telegram, которая уже активно используется против пользователей по всему миру. Главная особенность атаки в том, что злоумышленники не взламывают мессенджер и не подделывают его интерфейс, а аккуратно используют официальные механизмы аутентификации Telegram.
Как выяснили аналитики компании CYFIRMA, атакующие регистрируют собственные API-ключи Telegram (api_id и api_hash) и с их помощью инициируют реальные попытки входа через инфраструктуру самого мессенджера. Дальше всё зависит от того, как именно жертву заманят на фишинговую страницу.
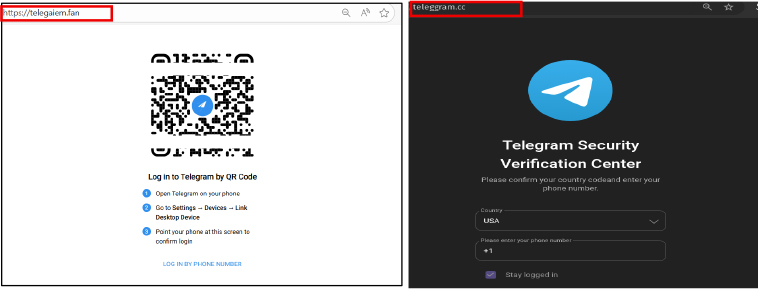
Всего специалисты наткнулись на два подобных сценария. В первом случае пользователю показывают QR-код в стиле Telegram, якобы для входа в аккаунт. После сканирования кода в мобильном приложении запускается легитимная сессия, но уже на стороне злоумышленника.
Во втором варианте жертву просят вручную ввести номер телефона, одноразовый код или пароль двухфакторной защиты. Все эти данные тут же передаются в официальные API Telegram.
Ключевой момент атаки наступает позже. Telegram, как и положено, отправляет пользователю системное уведомление в приложении с просьбой подтвердить вход с нового устройства. И вот тут в дело вступает социальная инженерия. Фишинговый сайт заранее подсказывает, что это якобы «проверка безопасности» или «обязательная верификация», и убеждает нажать кнопку подтверждения.
В итоге пользователь сам нажимает «Это я» и официально разрешает доступ к своему аккаунту. Никакого взлома, обхода шифрования или эксплуатации уязвимостей не требуется: сессия выглядит полностью легитимной, потому что её одобрил владелец аккаунта.
По данным CYFIRMA, кампания хорошо организована и построена по модульному принципу. Бэкенд централизованный, а домены можно быстро менять, не затрагивая логику атаки. Такой подход усложняет обнаружение и блокировку инфраструктуры.
После захвата аккаунта злоумышленники, как правило, используют его для рассылки фишинговых ссылок контактам жертвы, что позволяет атаке быстро распространяться дальше — уже от лица доверенного пользователя.



