













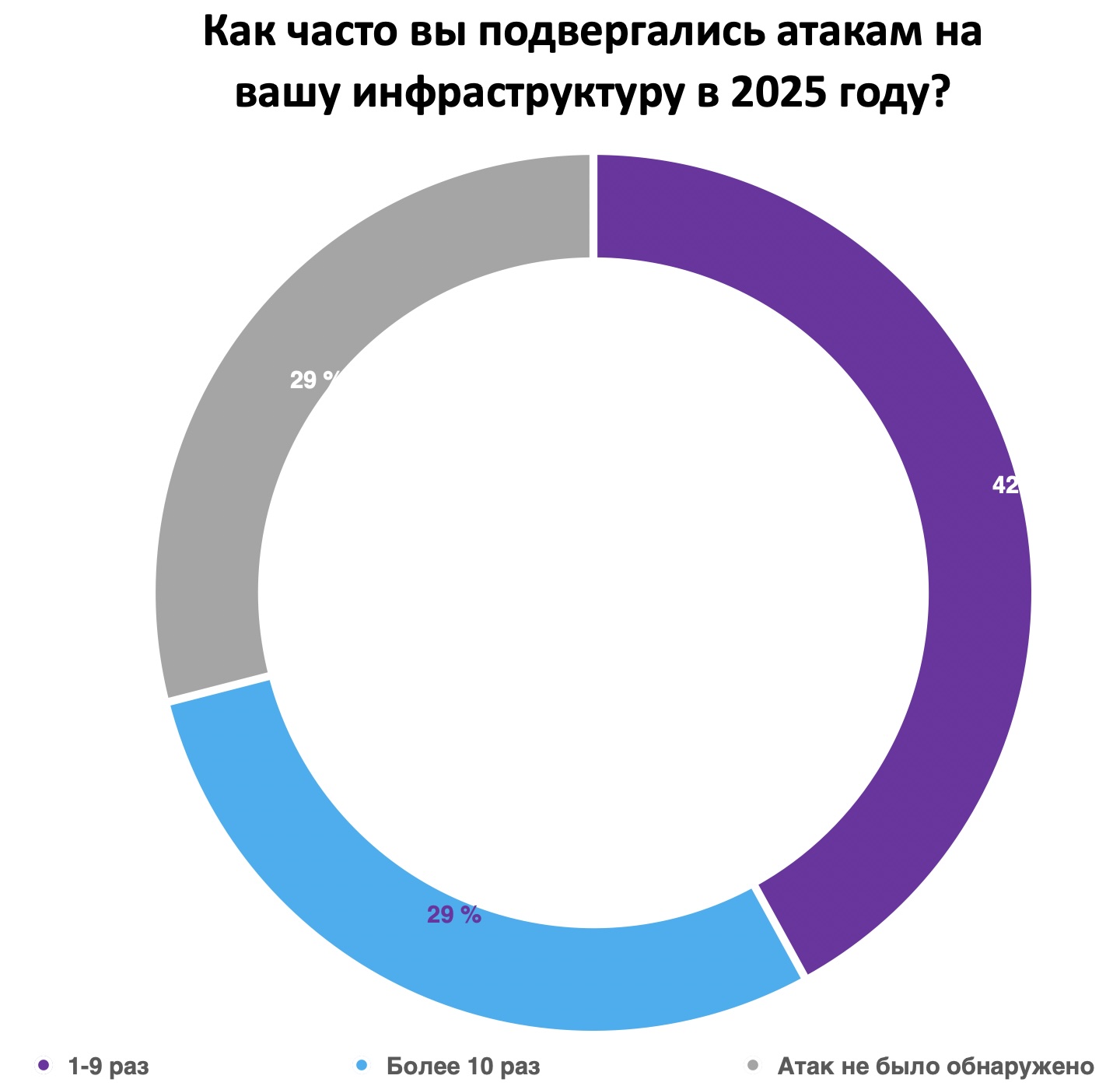
Почти треть российских компаний в 2025 году пережили более десяти кибератак на свою инфраструктуру. Об этом говорят результаты опроса, проведённого Центром компетенций сетевой безопасности компании «Гарда». Согласно данным исследования, 29% респондентов сообщили о десяти и более атаках, ещё у 42% инциденты происходили от одного до девяти раз.
При этом 29% участников заявили, что не фиксировали атак вовсе. В «Гарде» отмечают: это не обязательно означает их отсутствие — возможно, дело в недостаточном уровне мониторинга событий информационной безопасности.
Самыми распространёнными угрозами остаются фишинг и социальная инженерия — с ними сталкивались 69% опрошенных компаний.
На втором месте — вредоносные программы, включая инфостилеры, трояны и шифровальщики (56%). DDoS-атаки затронули почти треть участников опроса — 31%.
Отдельный блок опроса был посвящён тому, какие атаки труднее всего обнаружить и остановить. Лидируют здесь атаки с использованием уязвимостей нулевого дня — их назвали самыми проблемными 68% респондентов.
На втором месте — атаки внутри периметра с применением легитимных учётных записей (45%). Также компании отмечают сложности с выявлением скрытных вредоносных инструментов и атак, идущих через внешние сервисы с низким уровнем защиты.
По словам руководителя продукта «Гарда TI Feeds» Ильи Селезнёва, результаты опроса показывают очевидную тенденцию: киберугрозы развиваются быстрее, чем традиционные меры защиты.
Он подчёркивает, что в таких условиях всё большую роль играет проактивный подход и работа с актуальными данными об угрозах — от поиска фишинговых доменов и скомпрометированных учётных данных до выявления утечек персональных данных и исходного кода ещё до того, как ими воспользуются злоумышленники.
В целом результаты опроса подтверждают: даже если атаки «не видны», это не значит, что их нет. А фокус на обнаружение и предотвращение становится не менее важным, чем реагирование на уже произошедшие инциденты.



