













Исследователи из Cisco Talos рассказали о ранее неизвестном вредоносном фреймворке под названием DKnife, который как минимум с 2019 года используется в шпионских кампаниях для перехвата и подмены сетевого трафика прямо на уровне сетевых устройств.
Речь идёт не о заражении отдельных компьютеров, а о компрометации маршрутизаторов и других устройств, через которые проходит весь трафик пользователей.
DKnife работает как инструмент постэксплуатации и предназначен для атак формата «атакующий посередине» («adversary-in-the-middle») — когда злоумышленник незаметно встраивается в сетевой обмен и может читать, менять или подсовывать данные по пути к конечному устройству.
Фреймворк написан под Linux и состоит из семи компонентов, которые отвечают за глубокий анализ пакетов, подмену трафика, сбор учётных данных и доставку вредоносных нагрузок.
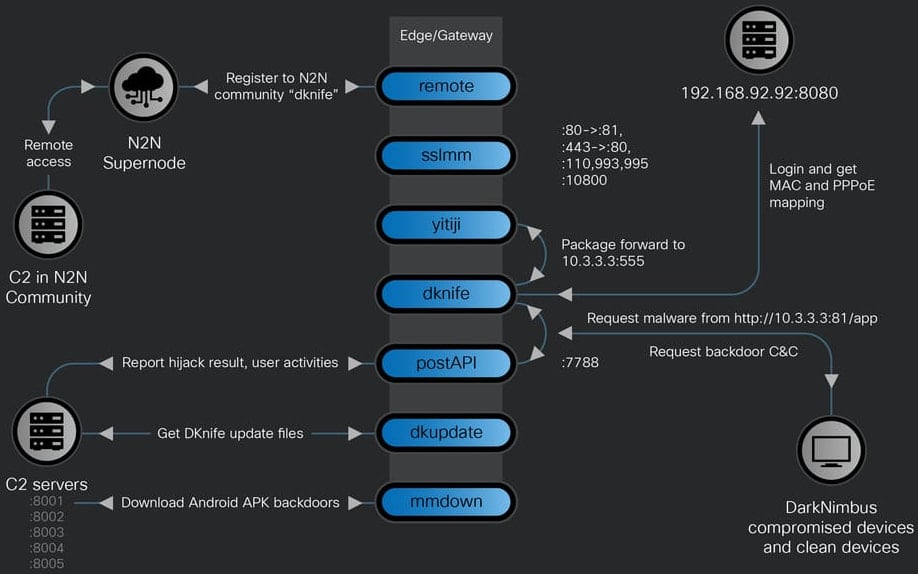
По данным Talos, в коде DKnife обнаружены артефакты на упрощённом китайском языке, а сам инструмент целенаправленно отслеживает и перехватывает трафик китайских сервисов — от почтовых провайдеров и мобильных приложений до медиаплатформ и пользователей WeChat. Исследователи с высокой уверенностью связывают DKnife с APT-группировкой китайского происхождения.
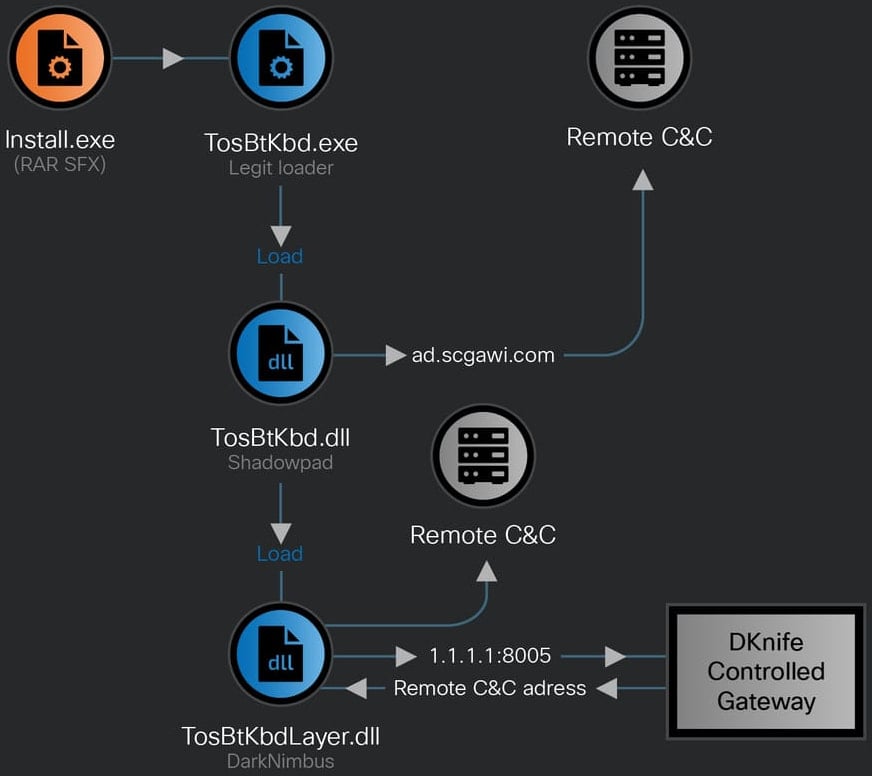
Как именно атакующие получают доступ к сетевому оборудованию, установить не удалось. Однако известно, что DKnife активно взаимодействует с бэкдорами ShadowPad и DarkNimbus, которые уже давно ассоциируются с китайскими кибершпионскими операциями. В некоторых случаях DKnife сначала устанавливал подписанную сертификатом китайской компании версию ShadowPad для Windows, а затем разворачивал DarkNimbus. На Android-устройствах вредоносная нагрузка доставлялась напрямую.
После установки DKnife создаёт на маршрутизаторе виртуальный сетевой интерфейс (TAP) и встраивается в локальную сеть, получая возможность перехватывать и переписывать пакеты «на лету». Это позволяет подменять обновления Android-приложений, загружать вредоносные APK-файлы, внедрять зловреды в Windows-бинарники и перехватывать DNS-запросы.
Функциональность фреймворка на этом не заканчивается. DKnife способен собирать учётные данные через расшифровку POP3 и IMAP, подменять страницы для фишинга, а также выборочно нарушать работу защитных решений и в реальном времени отслеживать действия пользователей.
В список попадает использование мессенджеров (включая WeChat и Signal), картографических сервисов, новостных приложений, звонков, сервисов такси и онлайн-покупок. Активность в WeChat анализируется особенно детально — вплоть до голосовых и видеозвонков, переписки, изображений и прочитанных статей.
Все события сначала обрабатываются внутри компонентов DKnife, а затем передаются на командные серверы через HTTP POST-запросы. Поскольку фреймворк размещается прямо на сетевом шлюзе, сбор данных происходит в реальном времени.


