Пользователи могут получить возможность запрещать компаниям собирать о себе «большие данные». Такая возможность может появиться в законодательстве по регулированию больших пользовательских данных, рассказал в интервью РБК помощник президента Игорь Щеголев.
Как рассказал помощник президента Игорь Щеголев в интервью РБК, в разрабатываемом сейчас законе о «больших пользовательских данных» может появиться возможность для пользователей запретить использование данных о себе операторам связи и другим компаниям.
«Пользователи, когда подписывались под пользовательскими соглашениями, понимали, что их данные нужны для того-то и того-то. Но с течением времени их стали использовать по-другому. У людей должно быть понимание, что о них собирается и для каких целей это используется. Должна быть возможность сказать: «Для этого я готов такие-то данные предоставлять и готов, чтобы они таким образом использовались, а для этого не готов. Поэтому, будьте любезны, эти данные обо мне больше не используйте», — рассказал Щеголев. По его словам, они выступают не за введение запрета на подобную практику, а за то, «чтобы у пользователя появилось больше возможностей влиять на судьбу тех данных, которые о нем получены».
Помощник президента отметил, что с развитием промышленного интернета и интернета вещей объем данных, по которым можно будет однозначно вычислить человека, с которым эти данные связаны, будет увеличиваться. Эти данные не всегда могут быть квалифицированы напрямую как персональные, но часть из них «находится на грани, в серой зоне», которая пока не отрегулирована,
В ноябре 2016 года руководитель Роскомнадзора Александр Жаров заявил, что рабочая группа по вопросам развития интернета при администрации президента, которую возглавляет Игорь Щеголев, начала разработку законопроекта, регулирующего работу с «большими пользовательскими данными». Четкого определения этого понятия пока не существует. Как объяснял представитель рабочей группы, это все данные о пользователе, которые собирают информационные системы и устройства, в том числе профили пользователей на интернет-ресурсах. По мнению главы Роскомнадзора, к этой категории данных можно отнести практически всю информацию о геолокации, биометрии, а также о пользовательском поведении на различных сайтах.
«Все это является предметом анализа транснациональных интернет-компаний и, очевидно, требует регулирования, как сейчас работает закон «О персональных данных», — говорил Жаров.
Под персональными данными понимают любую информацию, которую можно соотнести с конкретным физическим лицом. Оборот таких данных регулируется в России с 2007 года. В частности, с 1 сентября 2015 года закон требует хранить обработанные персональные данные россиян на территории России.
Операторы связи и интернет-компании, в свою очередь, оперируют понятием «большие данные», или big data, под которыми понимается анализ больших объемов обезличенной информации о пользователях. Представители «Ростелекома», мобильных операторов «большой тройки», интернет-компаний «Яндекс» и Mail.Ru Group ранее называли big data одним из направлений своего роста.
В частности, в феврале этого года «МегаФон» купил 15,2% Mail.Ru Group (соответствуют 63,8-процентной голосующей доле компании) за $740 млн, из которых $100 млн предстоит выплатить через год. Среди аргументов для сделки в том числе называлась возможность одной компании использовать «большие данные» другой.
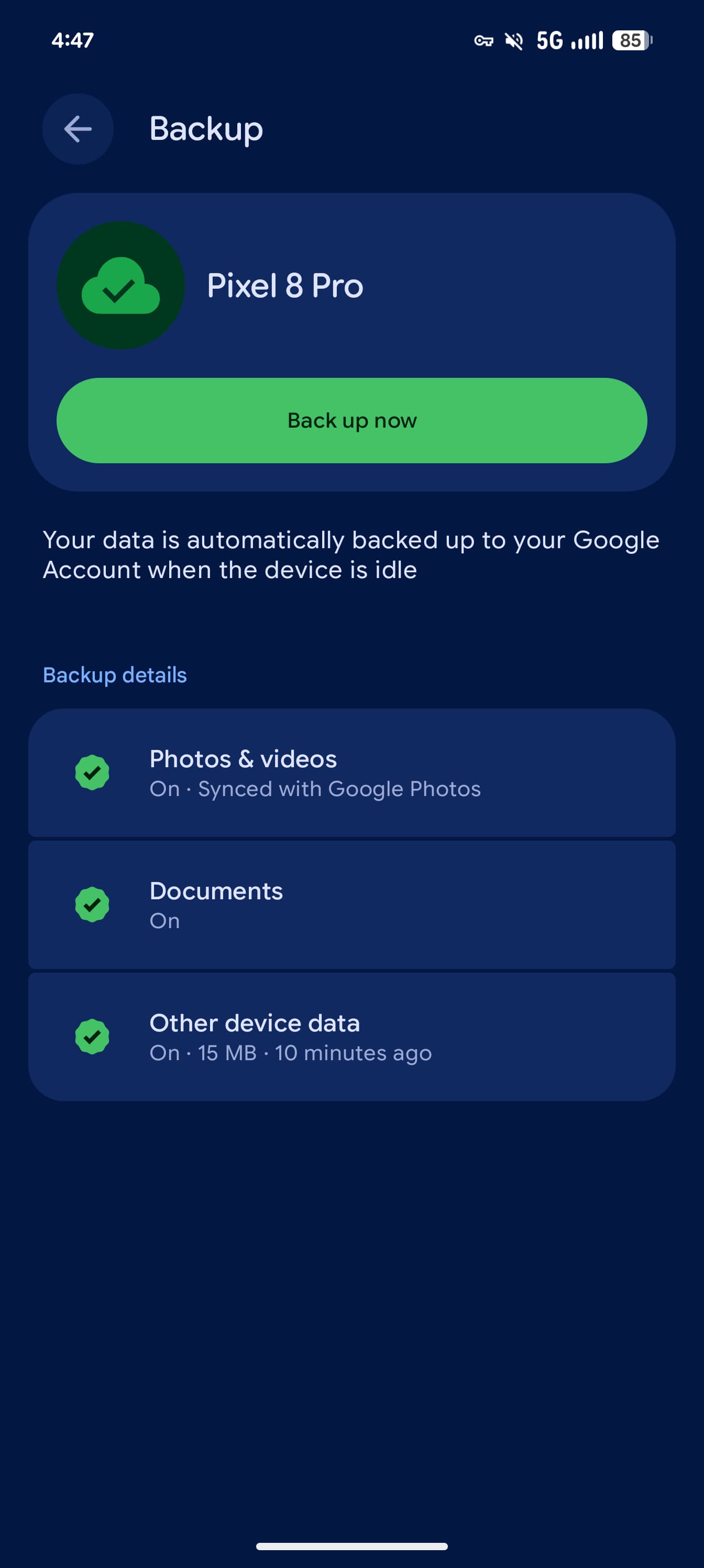
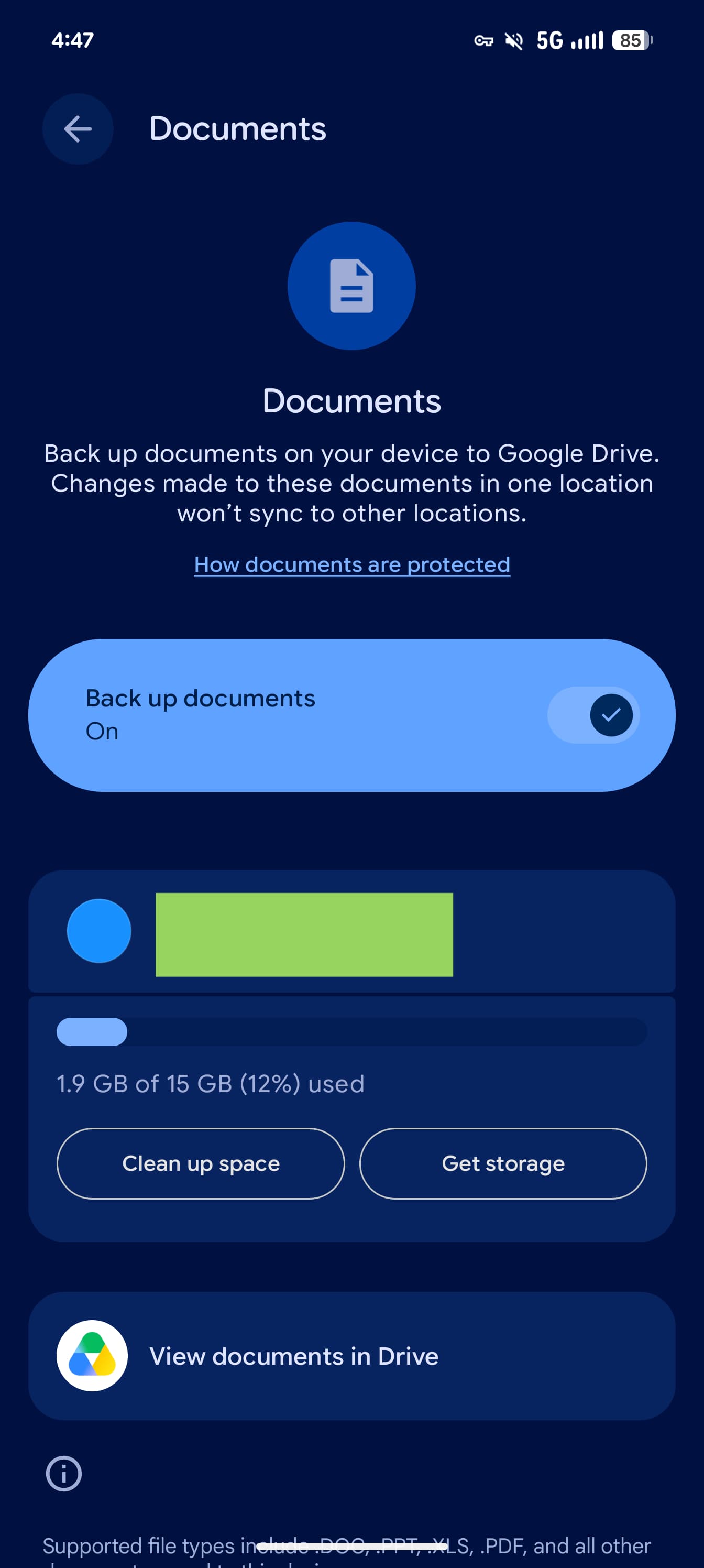
Google наконец запустила резервное копирование документов с Android-смартфонов в облако. Функция, которую компания готовила почти год, распространяется в стабильной версии Google Play Services 26.26.
На смартфонах Pixel новый пункт «Документы» появляется в разделе «Настройки» → «Аккаунты и резервное копирование» → «Резервное копирование Google».
По умолчанию функция выключена, Google всё-таки не стала без спроса кормить Drive содержимым папки Downloads.
После активации документы автоматически загружаются в новую папку Android backups на Google Drive. Внутри создаётся отдельный каталог с названием смартфона. Поддерживаются PDF, DOC, PPT, XLS, ZIP и другие форматы. Под горячую руку попадают даже APK-файлы из папки загрузок.
За облачный комфорт придётся расплачиваться гигабайтами: копии занимают место в хранилище Google Drive. На странице настройки можно проверить остаток, освободить пространство или, разумеется, купить дополнительное.
Есть и важный нюанс. Отключение резервного копирования не удаляет уже загруженные файлы, поэтому чистить папку на Drive придётся вручную. Полноценной синхронизации тоже нет: если изменить документ на смартфоне, его облачная копия автоматически не обновится, и наоборот.
Первые следы функции обнаружили ещё в августе 2025 года, а в феврале 2026-го Google официально упомянула её в обновлении Play System. Затем копирование документов появилось в бета-версии Play Services, и только теперь добралось до стабильной сборки.
Свидетельство о регистрации СМИ ЭЛ № ФС 77 - 68398, выдано федеральной службой по надзору в сфере связи, информационных технологий и массовых коммуникаций (Роскомнадзор) 27.01.2017 Разрешается частичное использование материалов на других сайтах при наличии ссылки на источник. Использование материалов сайта с полной копией оригинала допускается только с письменного разрешения администрации.