















Mozilla закрыла опасную уязвимость CVE-2026-10702 в JIT-компиляторе Firefox. Для атаки не требовалось нажимать подозрительные кнопки, отключать защиту или устанавливать файлы, хватало зайти на подготовленную злоумышленниками страницу.
Ошибка позволяла выполнить произвольный код внутри изолированного процесса браузера.
Исследователи Nebula Security также подтвердили, что уязвимость затрагивала Tor Browser, если тот был собран на базе уязвимой версии Firefox. Точные релизы Tor пока не названы.
Проблема появилась в Firefox 147 и сохранялась вплоть до версии 151.0.2. Mozilla оценила её опасность как высокую и выпустила исправление в Firefox 151.0.3. В Firefox ESR 140.12 ошибочного кода нет.
Дыра скрывалась в механизме оптимизации JavaScript. Браузер считал одну из операций безобидным чтением памяти, хотя та могла заменить буфер объекта и освободить старый. Оптимизатор продолжал использовать уже протухший указатель, а дальше исследователи превращали эту путаницу в чтение и запись произвольной памяти.
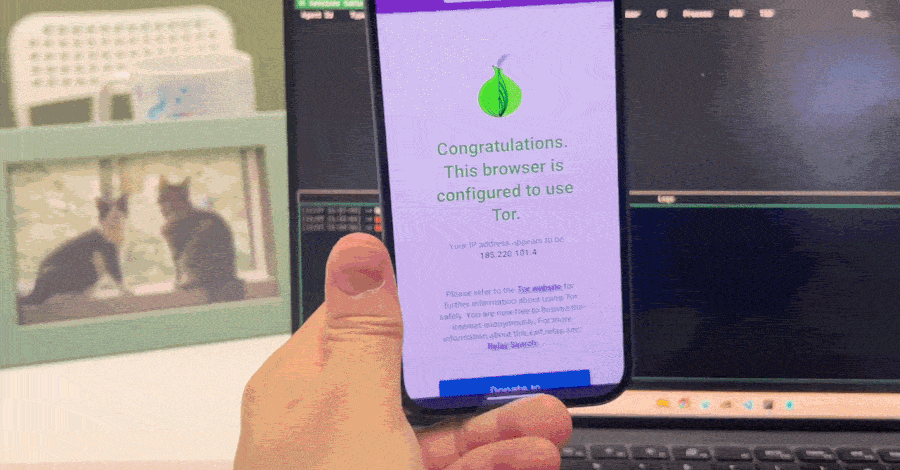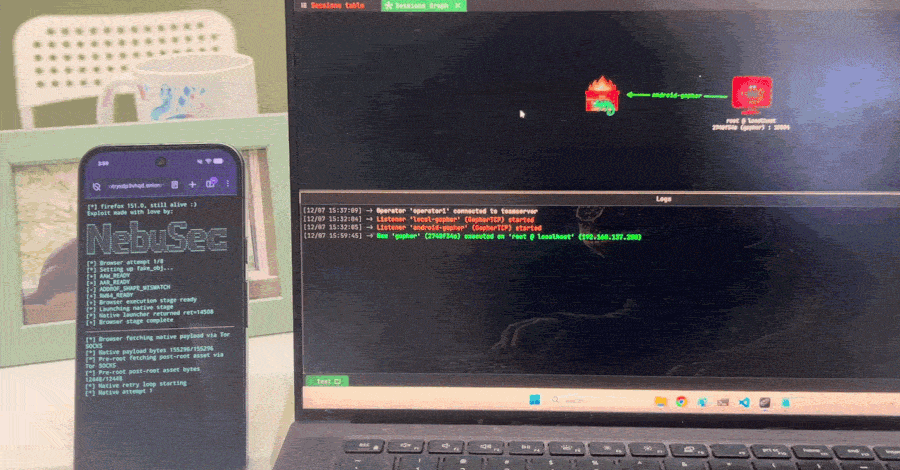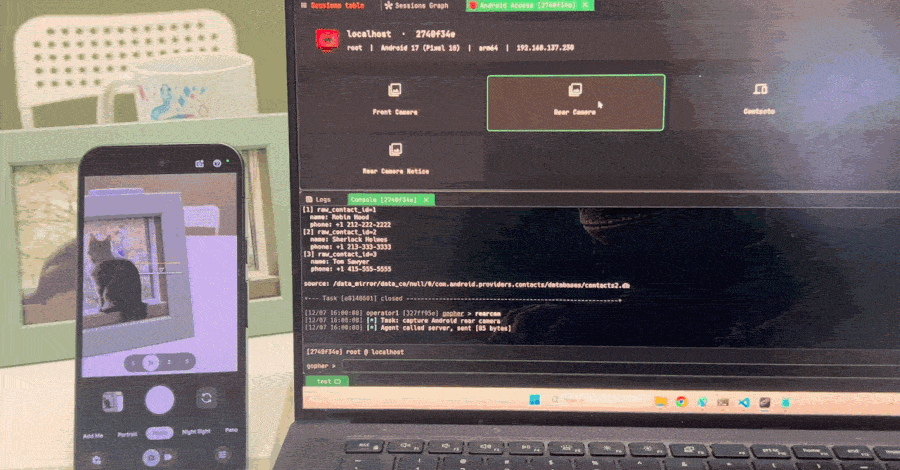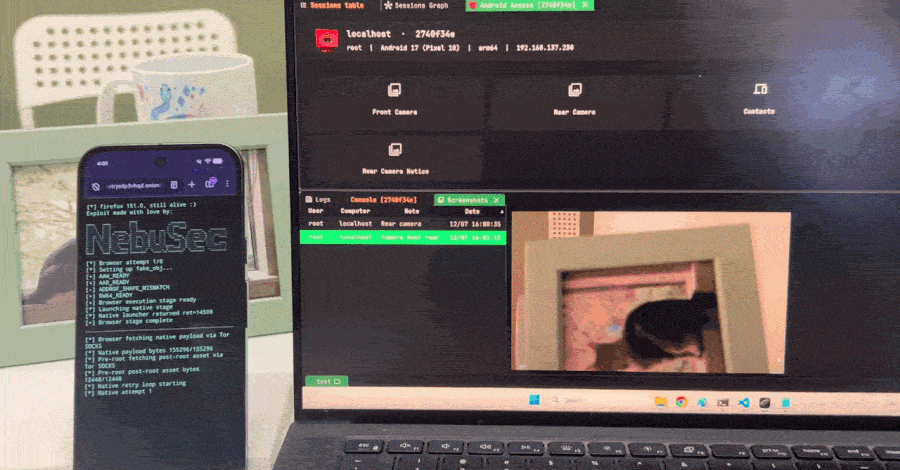
Nebula опубликовала эксплойт и включила его в цепочку IonStack для ARM64-устройства с Android 17. Firefox обеспечивал первый заход, а отдельная уязвимость Linux-ядра CVE-2026-43499, она же GhostLock, позволяла вырваться из браузерной песочницы и получить root. Обновление Firefox закрывает входную дверь, но саму GhostLock не исправляет.
По словам исследователей, браузерная ошибка не привязана к ARM: отдельные этапы работают и на x86, хотя полную цепочку для этой архитектуры пока не собрали.
Доказательств эксплуатации CVE-2026-10702 против обычных пользователей на момент публикации нет. Но после выхода публичного кода ждать приглашения не стоит: Firefox лучше обновить до актуальной версии.



