














Киберпреступники решили заработать на очередях за топливом. Специалисты «Эфшесть/F6» обнаружили более 60 фишинговых сайтов, которые маскируются под карты АЗС, игровые сервисы, маркетплейсы и видеохостинги. Схема у всех одна. Пользователю обещают показать, где есть бензин, выдать электронный талон на заправку или подарить бонусы в игре.
Для этого просят указать номер телефона, а затем ввести код из СМС. После этого мошенники получают доступ к аккаунту в мессенджере. Фейковые карты АЗС выглядят вполне убедительно.
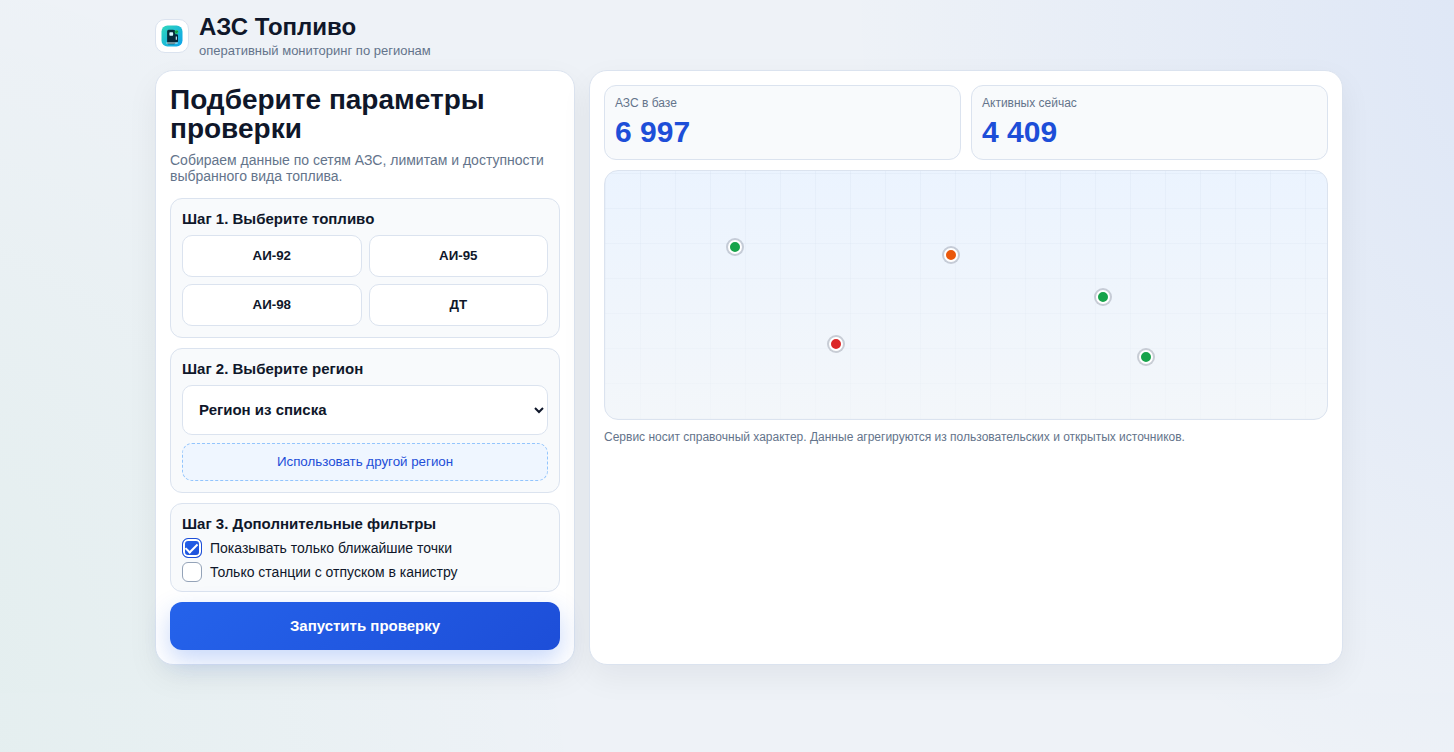
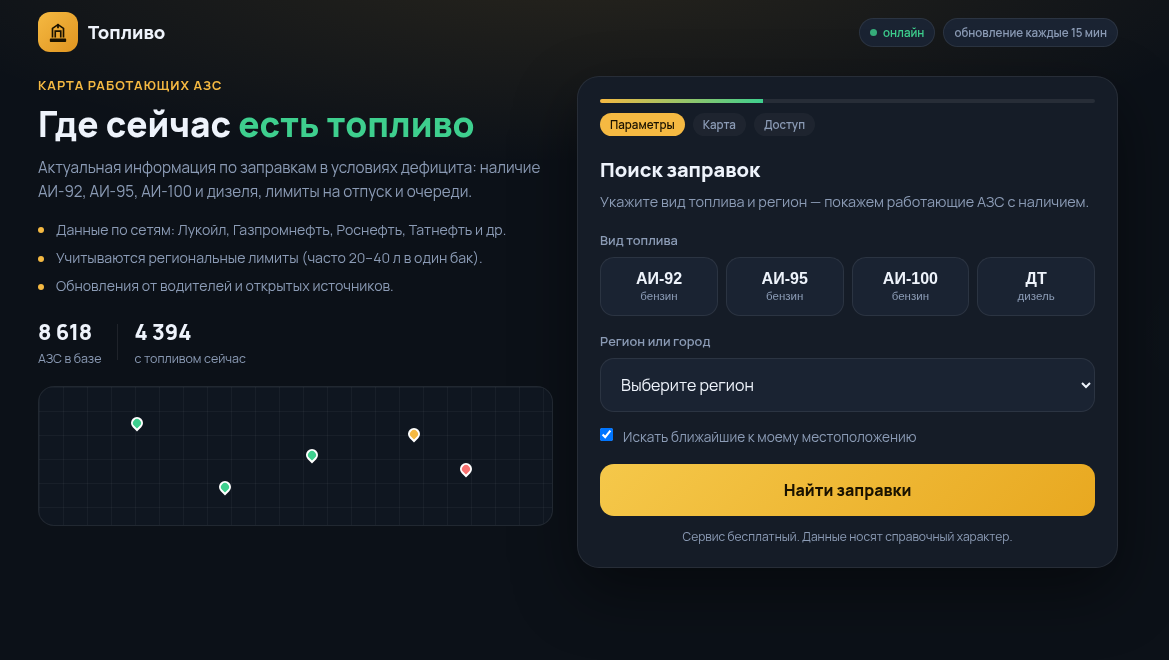
На сайте предлагают выбрать вид топлива и регион, затем якобы находят несколько заправок. Но сам список не показывают. Вместо него появляется форма «подтверждения номера». В другом варианте преступники копируют оформление настоящего сервиса и требуют авторизацию ради несуществующего электронного талона.
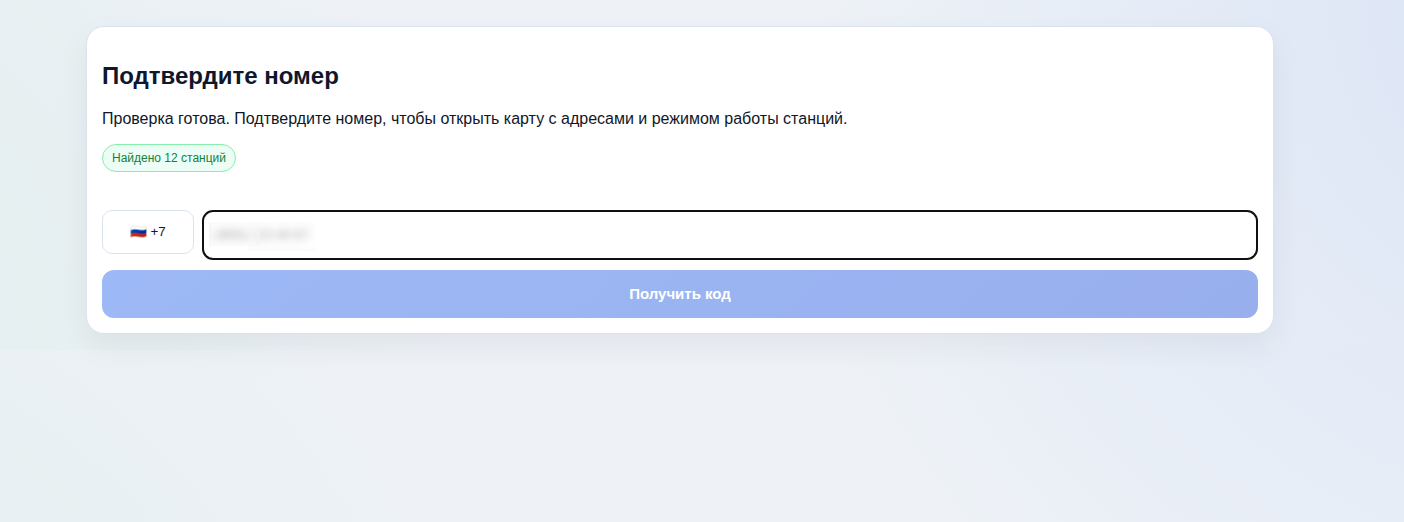
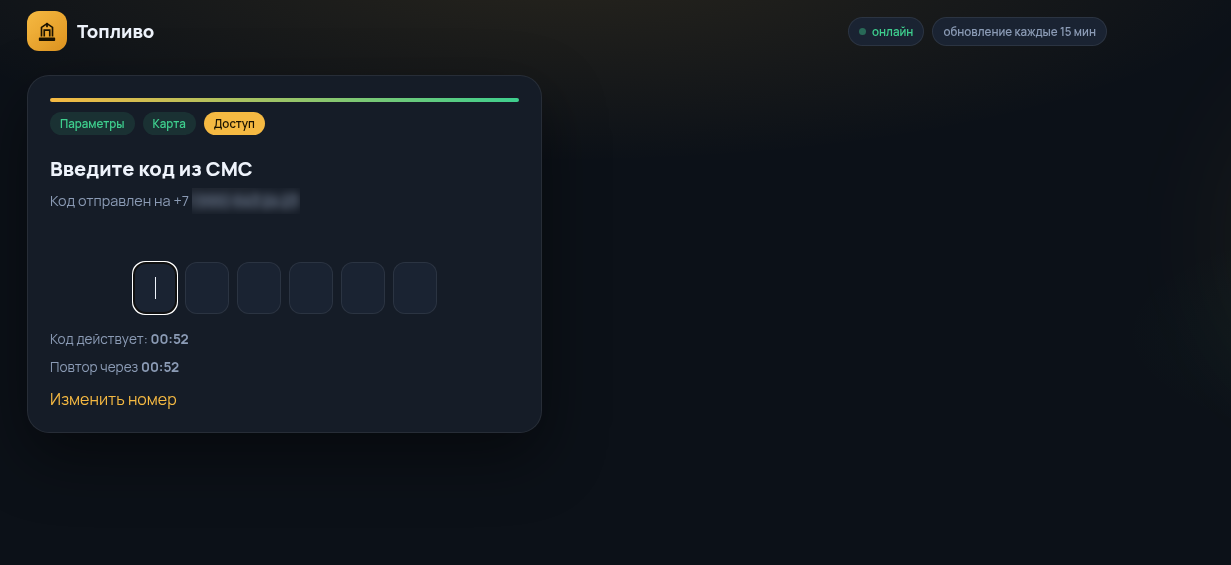
Получив код, злоумышленники могут читать переписку, скачивать фото, видео и документы, просматривать контакты и рассылать сообщения от имени жертвы. Иногда владелец даже не сразу замечает взлом: доступ к аккаунту у него сохраняется, пока мошенники тихо хозяйничают внутри.
Та же сеть атакует и детей. Под видом Brawl Stars пользователям предлагают бесплатные ящики и игровую валюту после входа через мессенджер.
Более половины найденных сайтов прикрываются брендами маркетплейсов, еще 19% — социальными платформами. Остальные маскируются под карты АЗС, игры, видеосервисы и доски объявлений.
Чаще всего фишинговые страницы размещают в доменных зонах .site, .click, .shop, .lol и .xyz. «Эфшесть/F6» уже направила их на блокировку, но новые адреса продолжают появляться.



