












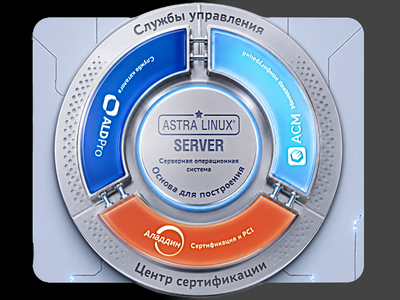
ГК «Астра» и компания «Аладдин» объявили о стратегическом партнёрстве и представили комплексное решение Astra Server Core со встроенными средствами управления доменной инфраструктурой и центром сертификации Aladdin Enterprise CA (eCA). Продукт предназначен для управления сложными гетерогенными ИТ-инфраструктурами, объединяющими рабочие станции, серверы и другие устройства на различных программных платформах — как отечественных, так и зарубежных.
Как рассказал на пресс-конференции, посвящённой подписанию соглашения, директор серверного ПО «Группы Астра» Алексей Фоменко, первоначально компании планировали объявить о партнёрстве на конференции ЦИПР-2026, проходившей в мае.
Однако, по его словам, среди большого количества анонсов это событие могло остаться незамеченным, поэтому его решили вынести в отдельную повестку спустя несколько недель после завершения форума.
Алексей Фоменко напомнил, что во времена доминирования Microsoft на рынке инфраструктурного ПО решения вендора были частью единого технологического стека, что обеспечивало высокий уровень управляемости инфраструктуры.
После ухода компании с российского рынка и начала масштабного импортозамещения многие организации столкнулись с серьёзными сложностями. Для решения различных задач внедрялись продукты разных российских разработчиков, при этом часть систем на базе Windows продолжала использоваться. В результате в ряде компаний сформировалась разрозненная инфраструктура и так называемая лоскутная модель информационной безопасности.
К 2025–2026 годам у многих российских заказчиков сформировался запрос на платформенные решения, построенные на базе отечественных технологий. Это, в свою очередь, стимулировало создание технологических альянсов между разработчиками, одним из которых стало партнёрство ГК «Астра» и компании «Аладдин».
При разработке совместного решения стороны стремились обеспечить не только совместимость продуктов на момент запуска, но и её сохранение после обновлений. Ещё одной задачей стало создание безопасной инфраструктуры, готовой к использованию «из коробки».
Как отметил генеральный директор компании «Аладдин» Сергей Груздев, многие заказчики сегодня эксплуатируют гетерогенные инфраструктуры, в которых одновременно используются отечественные и зарубежные решения. При этом необходимо обеспечивать как безопасность, так и непрерывность работы систем, избегая появления единых точек отказа. По его словам, при построении подобных архитектур безопасность должна оставаться приоритетом, а функциональность — следовать за ней.
В состав Astra Server Core входят Astra Linux Server, служба каталогов ALD Pro, менеджер конфигураций ACM и корпоративный центр сертификации Aladdin Enterprise CA. В дальнейшем разработчики планируют дополнить платформу средствами защищённой групповой работы, модулем доверенной загрузки, инструментами многофакторной аутентификации и шифрования данных.
Astra Server Core уже доступна для предварительного заказа. Начало продаж запланировано на третий квартал 2026 года.
«Для инфраструктуры корпоративного уровня критически важен компонент, которого нам до сих пор не хватало, — полноценная PKI-инфраструктура. У компании "Аладдин" накоплена одна из самых глубоких экспертиз в этой области и сформирован широкий портфель решений. Это позволяет заказчикам не собирать доверенную архитектуру по частям и не сталкиваться с проблемами совместимости компонентов на протяжении жизненного цикла системы. Объединяя нашу серверную платформу с компетенциями "Аладдина" в области PKI, мы создаём решение, которого рынок ждал с момента ухода Microsoft. Это безопасная инфраструктура, где управление пользователями, устройствами и сертификатами работает как единая система», — отметил Алексей Фоменко.
«Чтобы доверие и безопасность стали фундаментом, а не надстройкой, они должны быть встроены в системное и инфраструктурное ПО, а проектирование ИТ-инфраструктуры должно начинаться с безопасной архитектуры. Объединив наши компетенции в области информационной безопасности с инфраструктурной экспертизой "Группы Астра", мы интегрировали PKI непосредственно в основу экосистемы. В результате заказчики получают комплексное решение, которое позволяет изначально строить защищённую и управляемую инфраструктуру», — прокомментировал Сергей Груздев.
К слову, в новом выпуске AM Подкаст разобрали, почему рынок переходит от отдельных продуктов к платформенным решениям, как стратегический альянс «Группы Астра» и «Аладдин» меняет подход к построению ИТ-инфраструктуры и почему заказчики больше не хотят быть интеграторами собственного «зоопарка» решений.



