






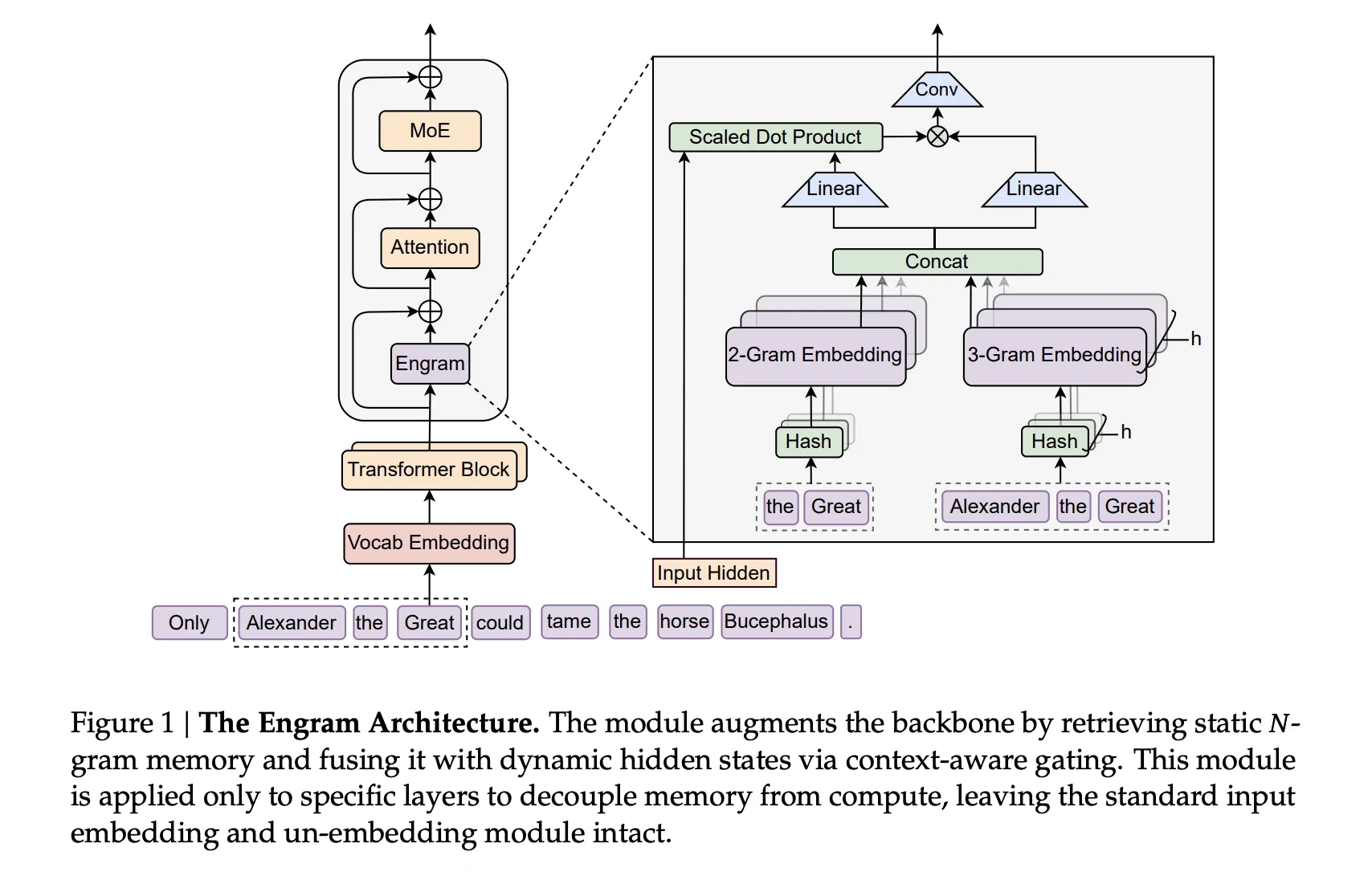







Мощностей технических средств противодействия угрозам (ТСПУ), которые Роскомнадзор использует для ограничения доступа к ресурсам, по мнению экспертов, оказалось недостаточно для одновременного воздействия на несколько крупных платформ. В результате ведомству приходится применять альтернативные технические методы.
Как считают эксперты, опрошенные РБК, именно этим может объясняться исчезновение домена YouTube из DNS-серверов Роскомнадзора, о котором накануне сообщил телеграм-канал «Эксплойт».
Управляющий директор инфраструктурного интегратора «Ультиматек» Джемали Авалишвили в комментарии РБК связал ситуацию с началом замедления Telegram:
«Фактически подконтрольные Роскомнадзору DNS-серверы перестали возвращать корректные адреса для домена youtube.com, что привело к невозможности подключения пользователей. Такой метод — часть технического арсенала Роскомнадзора для ограничения доступа к “неугодным” ресурсам. Он не нов и применяется в России наряду с блокировкой IP-адресов и пакетной фильтрацией».
Независимый эксперт телеком-рынка Алексей Учакин пояснил, что подобный подход может использоваться для экономии ресурсов, которых недостаточно для одновременного замедления двух крупных платформ:
«Поскольку все провайдеры обязаны использовать национальную систему доменных имен, то есть DNS-серверы под контролем Роскомнадзора, фактически появляется грубый, но достаточно надежный “выключатель” YouTube на территории России. При этом даже такая мера не перекрывает все способы обхода блокировок».
Замедление Telegram в России началось 10 февраля — об этом сначала сообщили СМИ со ссылкой на источники, а затем информацию официально подтвердил Роскомнадзор. Однако жалобы пользователей на снижение скорости работы мессенджера появились еще 9 февраля.



