






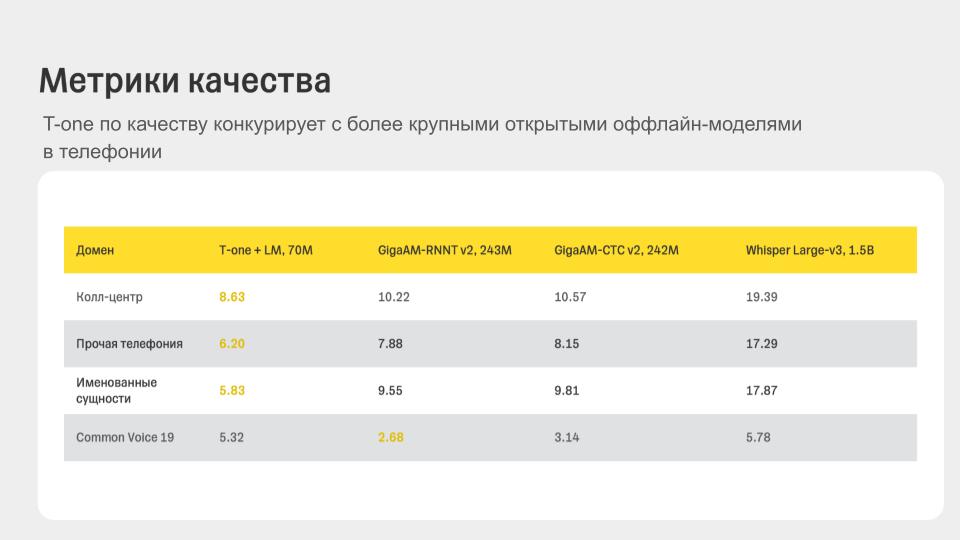






В Windows 11 закрыли довольно необычную уязвимость, затрагивающую родной «Блокнот». Проблема получила идентификатор CVE-2026-20841 и классифицирована как уязвимость удалённого выполнения кода (RCE). Проблема заключалась в способе обработки Markdown.
Атакующий мог создать специальный Markdown-файл (.md) с хитро оформленной ссылкой — например, на локальный исполняемый файл (через file://) или с использованием нестандартных URI вроде ms-appinstaller://.
Если пользователь открывал такой файл в «Блокноте» и нажимал Ctrl+клик по ссылке, программа запускала указанный файл без привычного предупреждения Windows.
По сути, достаточно было убедить человека открыть файл и кликнуть по ссылке, после чего код выполнялся с правами текущего пользователя. Это позволяло, например, запускать программы с удалённых SMB-шар или инициировать установку приложений. Именно отсутствие защитного предупреждения и стало главным элементом уязвимости.
После февральского набора патчей Microsoft изменила поведение «Блокнота». Теперь при попытке открыть ссылки с нестандартными протоколами — file:, ms-settings:, ms-appinstaller:, mailto: и другими — появляется предупреждающее окно. Без подтверждения пользователя запуск не произойдёт. Ссылки формата http:// и https:// открываются как обычно.
Интересно, что полностью блокировать нестандартные ссылки компания не стала, поэтому в теории пользователя всё ещё можно уговорить нажать «Да» в диалоге. Но теперь это уже вопрос социальной инженерии, а не «тихого» запуска без предупреждений.
Хорошая новость в том, что «Блокнот» в Windows 11 обновляется через Microsoft Store автоматически. Так что большинство пользователей, скорее всего, уже получили патч.



