








Согласно новым данным, которые собрала сеть ханипотов Microsoft, большинство использующих брутфорс киберпреступников пытаются угадать исключительно короткие пароли. Лишь небольшой процент атакующих берутся работать со сложными и длинными комбинациями.
Как объяснил Росс Бевингтон из Microsoft, ему удалось изучить данные, полученные в ходе анализа более 25 миллионов брутфорс-атак против учётных данных SSH. Всю эту информацию сеть Microsoft собрала за 30 дней работы.
«77% попыток подбора паролей были нацелены на комбинации с количеством символов от 1 до 7. Только 6% атак были направлены на пароли длиной 10 знаков и больше», — отмечает специалист.
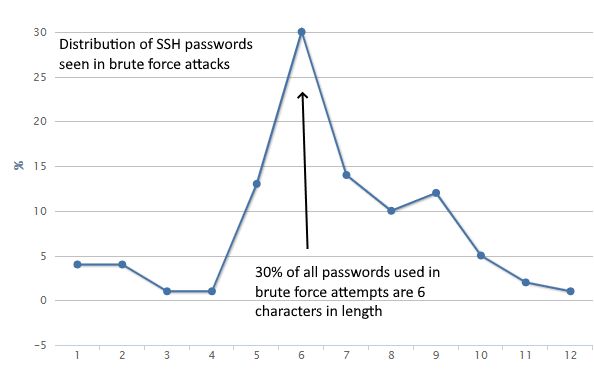
Также Бевингтон уточнил, что лишь в 7% случаев злоумышленники пытались подобрать пароли со спецсимволами, 39% атак пришлись на пароли хотя бы с одним числом и ни одной атаки не были зафиксировано на комбинации с пробельным символом.
По словам исследователя из Microsoft, длинные пароли со специальными символами можно считать более-менее защищёнными от брутфорс-атак. Единственное, что им может грозить — утечка.






