














Расширение Adblock for YouTube для Google Chrome, которым пользуются более 10 миллионов человек, оказалось в центре внимания исследователей в области кибербезопасности. Эксперты выяснили, что оно содержит механизм, позволяющий выполнять произвольный JavaScript-код практически на любом сайте.
Исследование опубликовала компания Island. По её данным, само расширение исправно блокирует рекламу на YouTube, однако в его архитектуре есть скрытая возможность удалённо активировать внедрение скриптов.
Причём для этого разработчику достаточно изменить серверную конфигурацию, выпускать новую версию расширения и проходить повторную проверку в Chrome Web Store не потребуется.
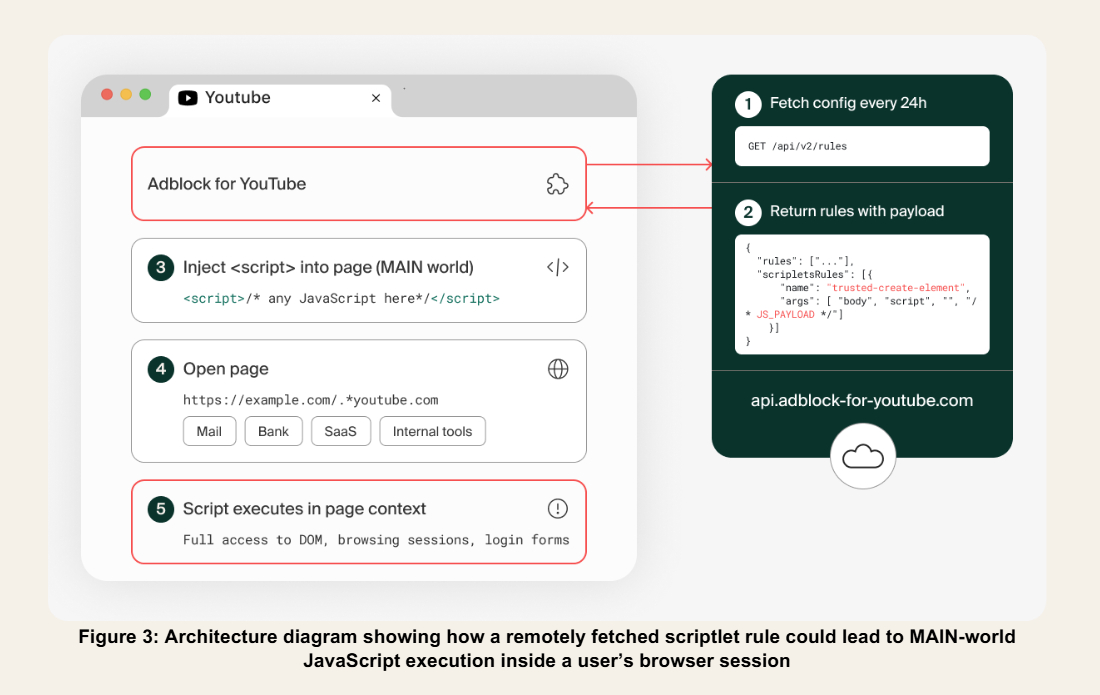
На момент анализа вредоносная функция не использовалась. Исследователи подчёркивают: доказательств того, что через неё уже распространялся вредоносный код, нет. Однако сам факт существования такого механизма вызывает вопросы.
Если подобную возможность активировать, расширение потенциально сможет читать содержимое веб-страниц, получать доступ к данным пользователей и выполнять действия от их имени в личных кабинетах, рабочих сервисах и административных панелях.
Ситуацию усугубляет тот факт, что блокировщики рекламы традиционно запрашивают разрешения для работы с содержимым сайтов. Кроме того, исследователи выяснили, что, несмотря на название, аддон запускается практически на всех посещаемых страницах, а не только на YouTube. Проверка того, находится ли пользователь на видеохостинге, реализована некорректно: достаточно, чтобы строка youtube.com встретилась где угодно в URL, даже в параметрах запроса.
Дополнительные вопросы вызывает история самого проекта. В 2018 году расширение сменило владельца, а в ранних версиях содержало SDK для показа рекламы. Несколько связанных с ним расширений ранее уже были удалены из Chrome Web Store после обнаружения вредоносной активности.
Разработчик Adblock for YouTube пока не прокомментировал выводы исследователей.



