













Google перевела функцию Device Bound Session Credentials (DBSC) в общую доступность для пользователей Chrome на Windows. Теперь эта защита работает в Chrome 146 и должна заметно осложнить жизнь тем, кто крадёт сессионные cookies, чтобы потом входить в чужие аккаунты без пароля.
Принцип работы DBSC кроется в том, что браузер не просто хранит cookie, а криптографически привязывает сессию к конкретному устройству.
Даже если зловред украдёт cookie из браузера, использовать их на другой машине будет уже гораздо труднее — по сути, они быстро потеряют ценность для атакующего.
Особенно актуально это на фоне популярности так называемых инфостилеров. Такие вредоносные программы собирают с заражённых устройств всё подряд: пароли, данные автозаполнения, токены и, конечно, cookie. Этого бывает достаточно, чтобы злоумышленник зашёл в учётную запись жертвы, даже не зная её пароль. Потом такие данные нередко перепродают другим участникам киберпреступного рынка.
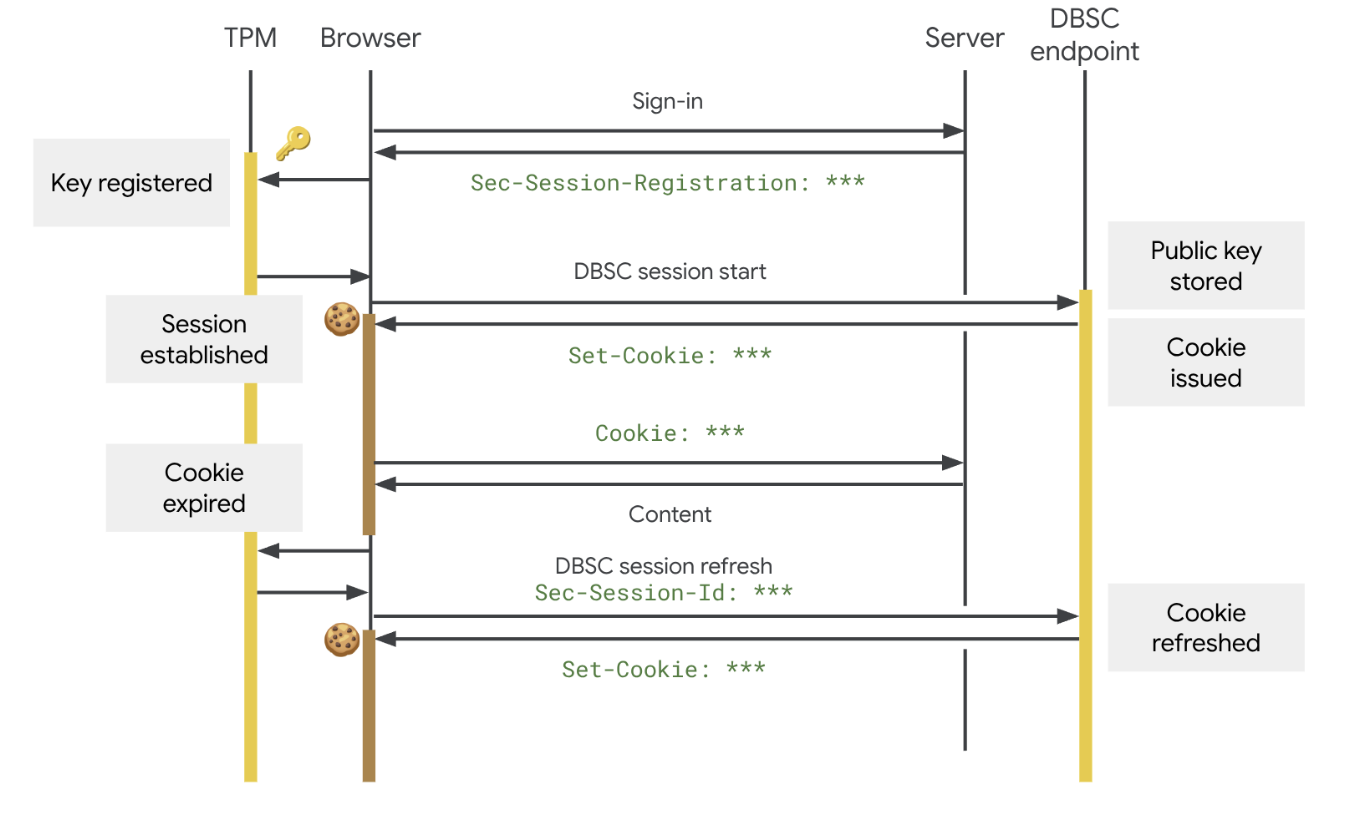
DBSC должна ломать именно такой сценарий. На Windows технология опирается на Trusted Platform Module, а на macOS — на Secure Enclave. С их помощью создаётся уникальная пара ключей, причём закрытый ключ не покидает устройство. Когда сайту нужно выдать новую короткоживущую cookie, Chrome должен доказать, что у него есть нужный закрытый ключ. Если ключ не на том устройстве, схема просто не срабатывает.
При этом Google подчёркивает, что технология задумана с упором на конфиденциальность. По данным компании, DBSC не должна превращаться в новый механизм слежки: сайт получает только тот минимум данных, который нужен для подтверждения владения ключом, без передачи постоянных идентификаторов устройства или дополнительных данных аттестации.
Есть и важная оговорка: если устройство не поддерживает безопасное хранение ключей, Chrome не ломает аутентификацию и просто откатывается к обычной схеме работы. То есть пользователи не должны столкнуться с внезапными сбоями входа только потому, что их железо не подходит под новую модель защиты.
Пока публичный запуск ограничен Windows-пользователями Chrome 146, но Google уже подтвердила, что поддержку macOS добавят в одном из следующих релизов. Компания также заявила, что после начала внедрения DBSC уже заметила заметное снижение случаев кражи сессий.



