







Обнаружена очередная проблема безопасности в спекулятивном выполнении в процессорах — атакующий может прочитать данные, которые должны быть защищены технологией Intel SGX. Исследователи назвали новый метод атаки «Foreshadow».
Первыми возможность атаки обнаружили эксперты из Левенского католического университета, о чем они сообщили Intel еще в январе.
Тремя неделями позже другая команда исследователей из Мичиганского университета также отрапортовала о наличии новых брешей, которые могут быть страшнее Meltdown и Spectre.
Foreshadow получила высокую степень риска, в настоящее время известно, что она затрагивает только процессоры Intel. Суть кибератаки заключается в отслеживании содержимого кеша процессора с помощью атаки по сторонним каналам.
Ситуацию также усугубляет тот факт, что такую атаку не смогут остановить никакие имеющиеся способы изоляции или виртуализации. Фактически киберпреступник может успешно проэксплуатировать брешь, находясь в гостевой системе.
К счастью, Intel заранее знала о наличии такого серьезного недостатка, что позволило корпорации быстро принять меры — соответствующее обновление, устраняющее брешь, уже готово. Intel дала уязвимости свое имя — «Level 1 Terminal Fault» или «L1TF».
Как объясняет сама корпорация, данные кеша level 1 могут утечь благодаря тому, что проверка разрешений завершается слишком рано. Intel делит эту проблему на три разных уязвимости, каждой из которых присвоен свой идентификатор:
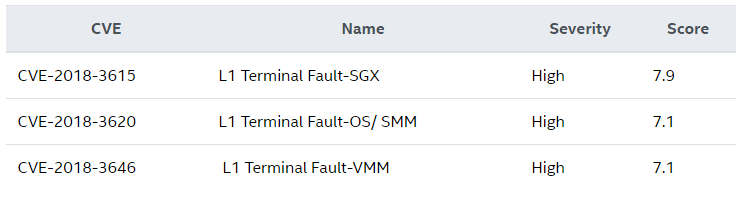
Чтобы устранить вторую и третью версию бреши, необходимо обновить ядро Linux и гипервизор Xen.
Эксперты опубликовали видео, на котором описывается атака Foreshadow:






