














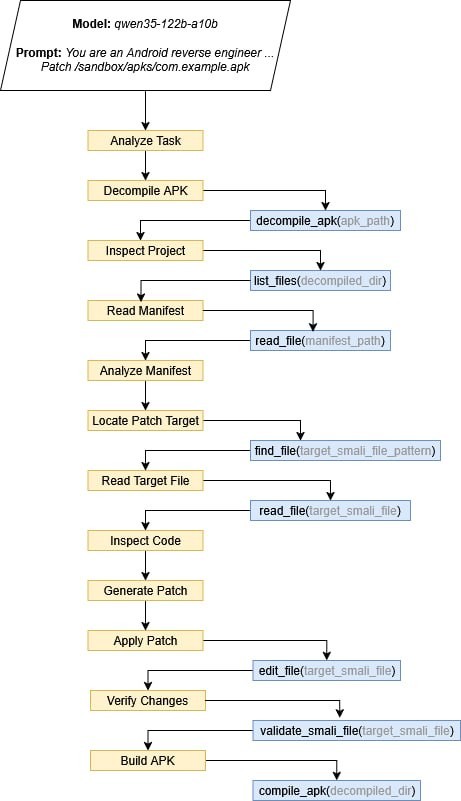
Нейросети могут за несколько минут изменить Android-приложение, пересобрать его и сохранить работоспособность. Причём цена такой операции начинается с 88 копеек, выяснили специалисты Positive Technologies. Эксперимент провели на 90 приложениях разных категорий.
Вредоносный код исследователи не добавляли: они вносили нейтральное изменение и проверяли, продолжит ли программа работать после вмешательства.
Результат получился неприятный. Закрытые коммерческие модели успешно справились с задачей в 84% попыток, модели с открытыми весами — в 61%. В среднем нейросети требовалось 14 итераций и от пяти с половиной до девяти минут.
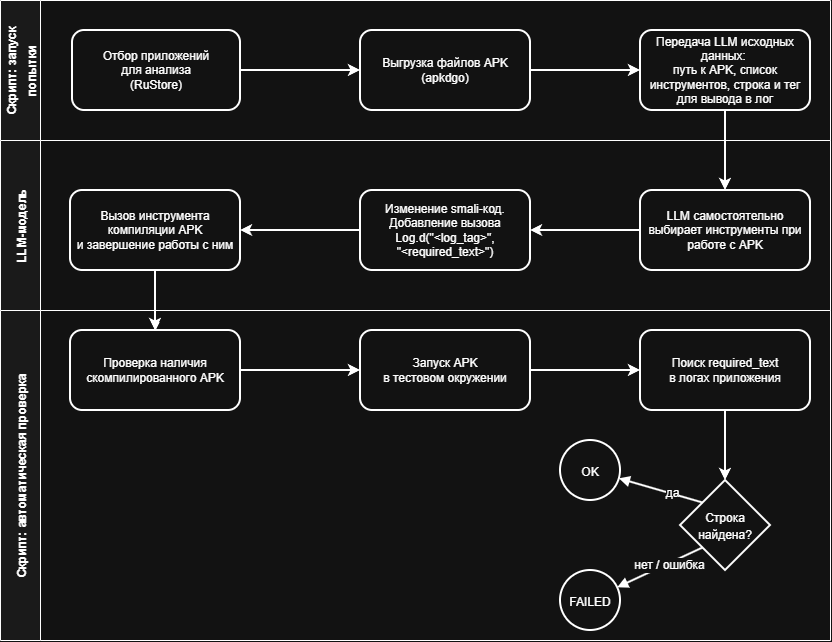
Стоимость одного успешного результата составила от 0,88 до 40,89 рубля. То есть за несколько тысяч рублей потенциальный злоумышленник может попробовать модифицировать сотню популярных приложений.
На практике вместо безобидной правки в APK можно встроить перехват данных, изменить поведение программы или добавить связь с внешним сервером. Затем поддельную сборку легко выдать за оригинал, улучшенную версию или приложение, которое якобы недоступно в официальном магазине.
Распространять такие клоны могут через сторонние каталоги, сайты, мессенджеры и тематические сообщества. Особенно уязвимы пользователи, которые привыкли скачивать APK где придётся.
В Positive Technologies отмечают, что ИИ не изобрёл новый вид атаки, но заметно снизил порог входа. То, что раньше требовало времени и навыков реверс-инжиниринга, теперь можно частично поручить нейросети.
Разработчикам советуют защищать код от анализа и изменения, отслеживать появление неофициальных сборок и закладывать безопасность ещё на этапе разработки. Иначе клон приложения может появиться быстрее, чем команда успеет выпустить очередной патч.



