













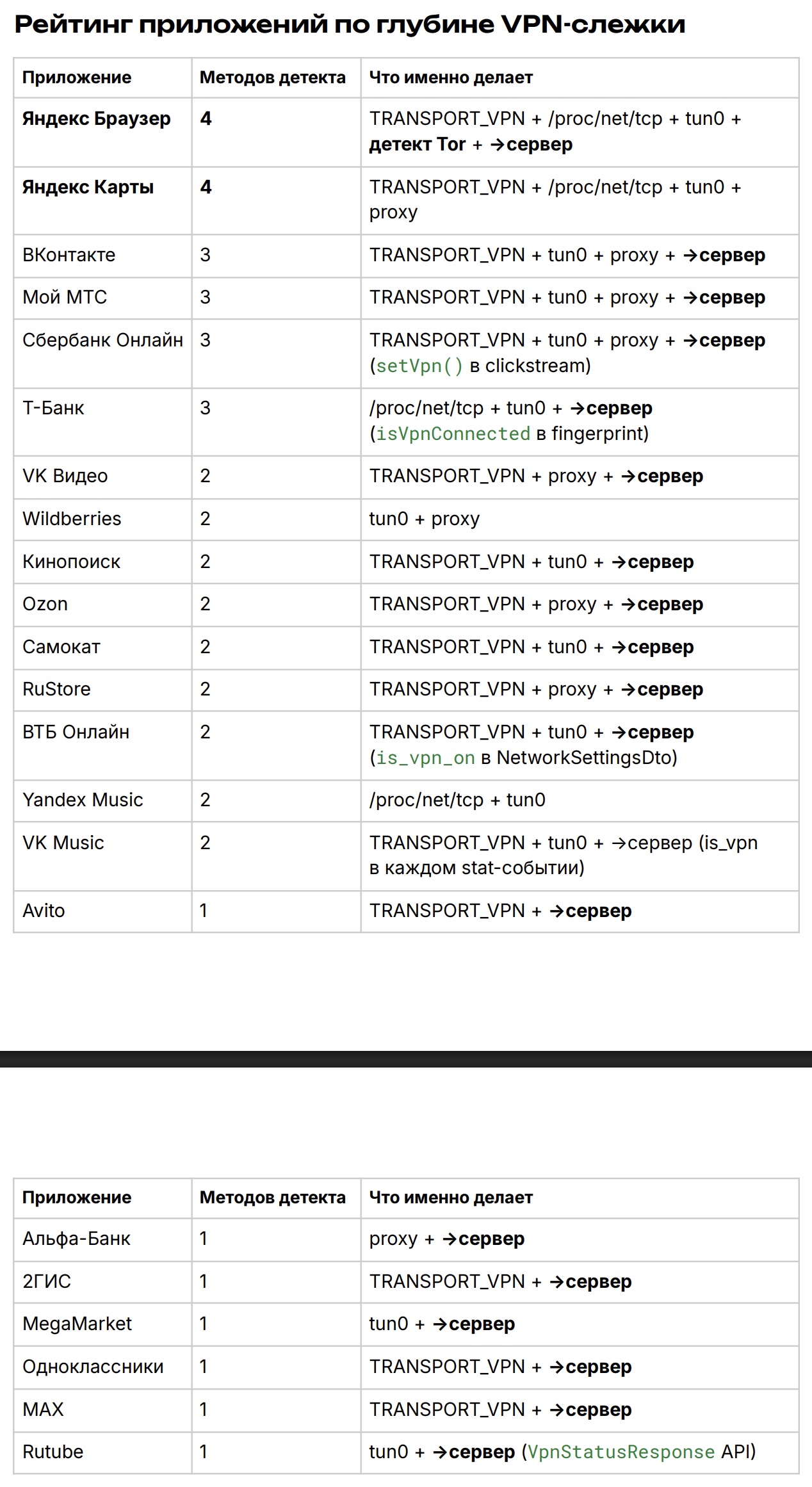
Эксперты RKS Global повторно проверили 30 популярных российских Android-приложений и выяснили, что теперь все они умеют детектировать VPN. Более того, часть приложений, судя по сетевым логам, отправляет такую информацию на свои серверы для дальнейшего анализа.
Семь приложений — Wildberries, «2ГИС», МТС, Ozon, «Мегамаркет», RuStore и «Одноклассники». Все они теперь могут получать полный список установленных VPN-клиентов на устройстве. Раньше такой подход встречался лишь в отдельных случаях.
Исследование называется «Выявление слежки в 30 популярных российских приложениях» (PDF). Специалисты изучали APK-файлы из RuStore и Google Play с помощью статического анализа: декомпилировали приложения и проверяли их по 68 контрольным точкам в 12 категориях. При этом авторы подчёркивают ограничение методики: динамического тестирования на реальных устройствах не проводилось.

Активизация таких проверок связана с рекомендациями регуляторов. Ранее Минцифры попросило операторов связи и ИТ-компании принимать меры против использования средств обхода блокировок. С 15 апреля многие российские платформы начали ограничивать доступ пользователям с включённым VPN, а реальный список таких сервисов оказался шире первоначальных ожиданий.
В Минцифры также заявляли, что российские сервисы доступны пользователям за рубежом. Если же сайт или приложение ошибочно требует отключить VPN, даже когда он не используется, пользователям советуют обращаться в поддержку конкретного сервиса.
Параллельно в открытом доступе появились тестовые проекты для Android, которые демонстрируют способы выявления VPN и прокси на устройстве. Среди них RKNHardering.



