Microsoft презентовала ИИ-модель, способную преобразовать текст в голос, который ей дали послушать всего 3 секунды. Получается очень похоже на оригинал, к тому же VALL-E (именно так назвали программу) умеет копировать интонации и добавлять естественные шумы. В “широкий прокат” VALL-E не пойдет, пока не придумают антипрограмму, способную распознавать робота.
Исследователи компании анонсировали программу VALL-E, которая синтезирует человеческий голос близко к оригиналу. Название сервиса созвучно известному американскому мультфильму про робота ВАЛЛ-И. Он очищал от мусора заброшенную людьми Землю, потом отправился в космос, вернулся и сумел спасти планету.
Для анализа искусственному интеллекту достаточно всего трехсекундного аудиопримера.
Создатели VALL-E говорят, что придумали программу в помощь приложениям, преобразующим текст в речь, когда нужно отредактировать какой-то отрывок в хорошем качестве. В этом случае программа может сымитировать то, что спикер на самом деле не говорил.
В Microsoft VALL-E называют моделью языка нейронного кода. Она построена на технологии EnCodec, которую корпорация Meta (признана экстремистской и запрещена на территории России) анонсировала в минувшем октябре.
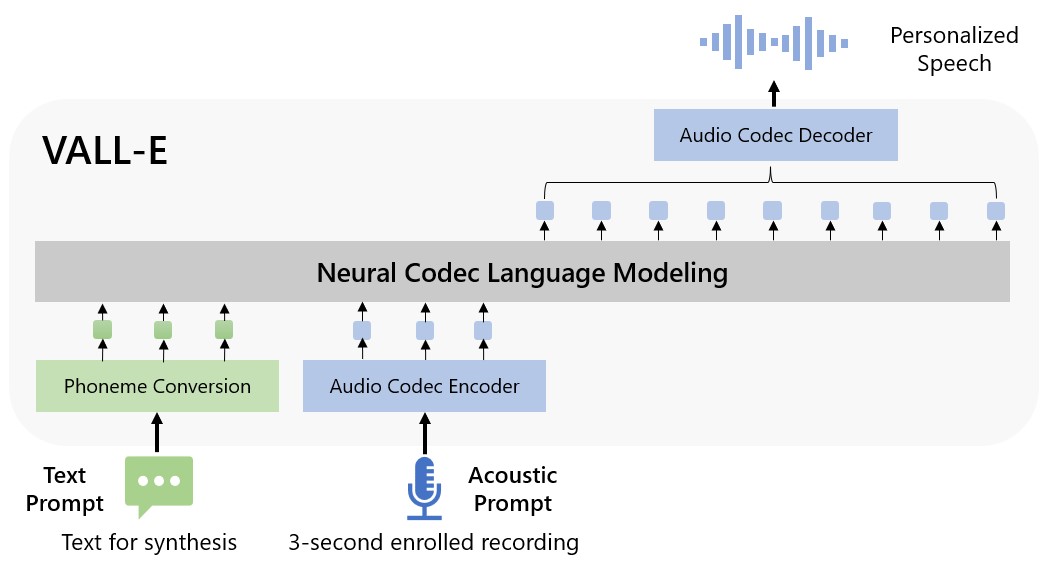
В отличие от других методов преобразования текста в речь, которые обычно используют сигналы, VALL-E генерирует дискретные коды аудиокодеков из текстовых и акустических подсказок. Программа анализирует, как “звучит” человек, разбивает эту информацию на отдельные компоненты (“токены”) и учится на этих данных.
“Чтобы синтезировать речь, VALL-E генерирует соответствующие акустические маркеры, взятые из трехсекундного аудиопримера, а также использует фонетические подсказки, которые мог бы использовать человек, если бы отрывок длился дольше, — говорится в анонсе Microsoft. — Сгенерированные акустические маркеры используются для синтеза окончательной формы сигнала с помощью соответствующего декодера нейронного кодека”.
Microsoft уже натренировала VALL-E на тысячах аудиокниг на английском языке. На странице сервиса можно прослушать трехсекундный образец, оригинал и речь от VALL-E.
Некоторые примеры всё ещё напоминают роботизированный голос, но есть и очень похожие на заданную человеческую речь.
Кроме того, VALL-E способна воспроизводить акустическое окружение. Например, синтезировать речь, как будто она звучит из телефонной трубки.
В Microsoft заявили, что понимают риски VALL-E и не будут делиться кодом с другими, пока не придумают детектор, способный отличать сублимированную речь от настоящей.
“Так как VALL-E может синтезировать речь, сохраняющую идентичность спикера, программа может нести потенциальные риски неправильного использования модели”, — признают создатели. Речь идет о подмене голосовой идентификации или выдаче себя за другого человека.
Риски снизит модель, позволяющая найти отличия и определить, был ли аудиоклип синтезирован VALL-E.
Американские ученые в сентябре предложили выявлять голосовые дипфейки с помощью флюидодинамики. В университете Флориды изучили достижения артикуляционной фонетики и разработали новую технику распознавания дипфейк-аудио — по отсутствию ограничений, влияющих на работу голосового аппарата человека. Созданный детектор способен определить подмену с точностью 92,4%.
Добавим, в ноябре Роскомнадзор заинтересовался разработкой НИУ ИТМО в области распознавания лжи по видеозаписи, а аналитики Сбера внесли Deepfake в одну из самых опасных технологий, способных угрожать кибербезопасности в перспективе ближайших пяти лет.