














WhatsApp (принадлежит корпорации Meta, признанной экстремистской и запрещённой в России) наконец-то добавляет аудио- и видеозвонки в веб-версию мессенджера. Раньше поговорить с компьютера можно было только через отдельное приложение, а браузер оставался для почитать и написать. Теперь этот пробел закрывают.
В WhatsApp Web появится вкладка «Звонки» с историей вызовов и избранными контактами.
Пользователям также станут доступны демонстрация экрана и реакции — почти полный набор возможностей настольного приложения. Заодно Meta научила звонки переезжать между устройствами без разрыва соединения. Например, разговор, начатый в браузере или на компьютере, можно будет продолжить на смартфоне.
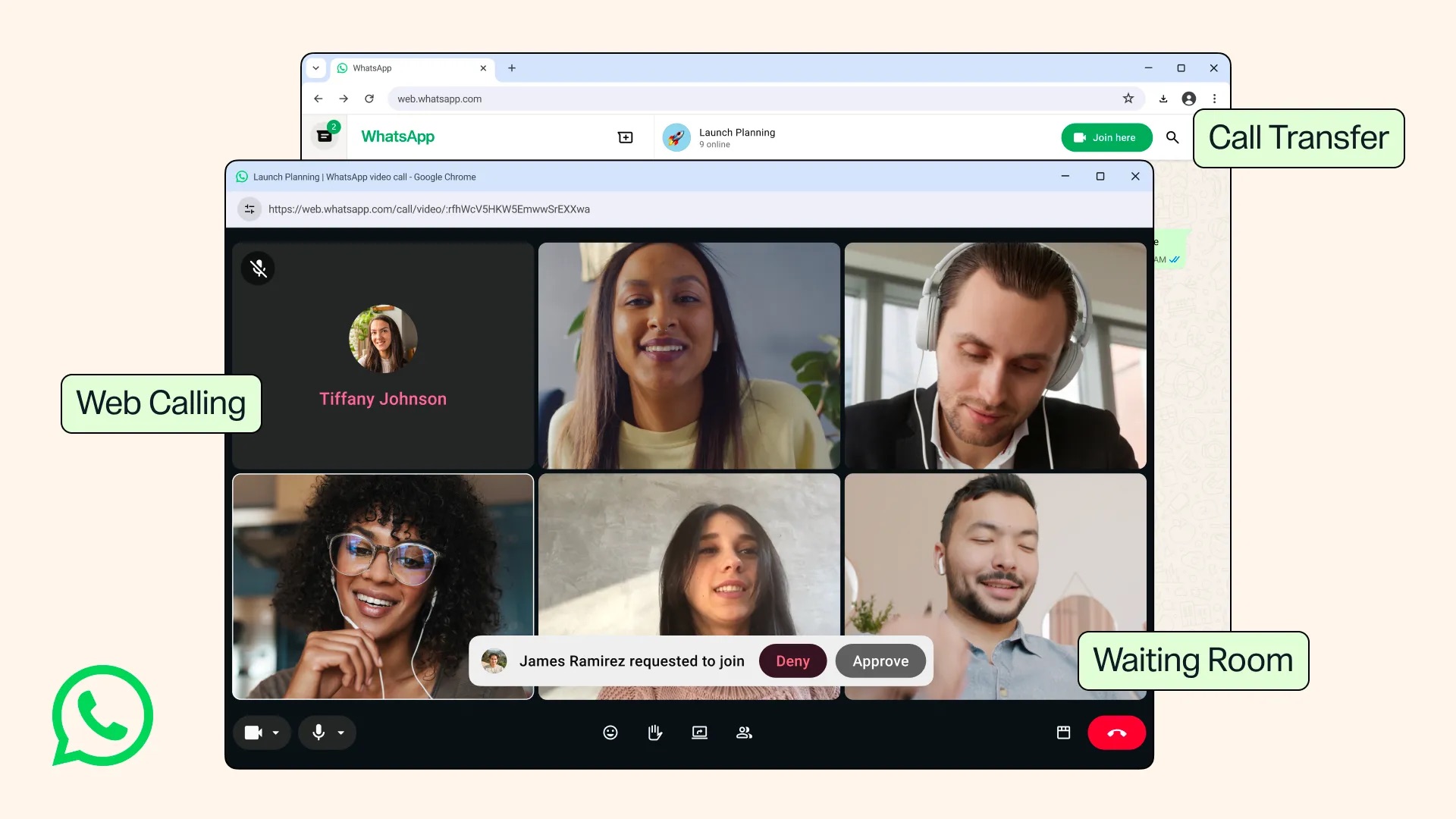
Для групповых созвонов появятся комнаты ожидания. Создатель ссылки сможет включить опцию «Требовать одобрения для входа», после чего впускать участников вручную или отправлять незваных гостей обратно за дверь.
Функция пригодится тем, кто использует WhatsApp для рабочих встреч и не хочет устраивать проходной двор.
Ещё одно обновление — подавление фонового шума. Мессенджер постарается отфильтровать гул людных помещений и другие посторонние звуки. Кроме того, видеозвонки начнут переходить в HD уже в первые секунды, а не после небольшой разминки в пикселях.
Недавно WhatsApp также открыл резервирование имён пользователей. После полноценного запуска функции звонить другим людям на разных платформах можно будет по нику, не раскрывая номер телефона.



