













Исследователи безопасности обнаружили 287 расширений для Google Chrome, которые, по их данным, тайно отправляли данные о посещённых пользователями сайтах на сторонние серверы. Суммарно такие расширения были установлены около 37,4 млн раз, что равно примерно 1% мировой аудитории Chrome.
Команда специалистов подошла к проверке не по описаниям в магазине и не по списку разрешений, а по фактическому сетевому поведению.
Для этого исследователи запустили Chrome в контейнере Docker, пропустили весь трафик через MITM-прокси и начали открывать специально подготовленные URL-адреса разной длины. Идея была простой: если расширение «безобидное» — например, меняет тему или управляет вкладками — объём исходящего трафика не должен расти вместе с длиной посещаемого URL.
А вот если расширение передаёт третьей стороне полный адрес страницы или его фрагменты, объём трафика начинает увеличиваться пропорционально размеру URL. Это измеряли с помощью собственной метрики. При определённом коэффициенте расширение считалось однозначно «сливающим» данные, при более низком — отправлялось на дополнительную проверку.
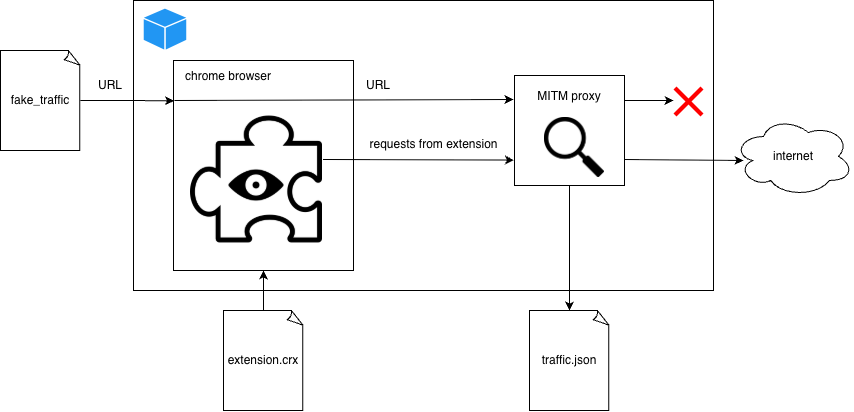
Работа оказалась масштабной: на автоматическое сканирование ушло около 930 процессорных дней, в среднем по 10 минут на одно расширение. Подробный отчёт и результаты опубликованы в открытом репозитории на GitHub, хотя авторы намеренно не раскрыли все технические детали, чтобы не облегчать жизнь разработчикам сомнительных аддонов.
Среди получателей данных исследователи называют как крупные аналитические и брокерские экосистемы, так и менее известных игроков. В отчёте фигурируют, в частности, Similarweb, Big Star Labs (которую авторы связывают с Similarweb), Curly Doggo, Offidocs, а также ряд других компаний, включая китайские структуры и небольших брокеров.
Проблема не ограничивается абстрактной «телеметрией». В URL могут содержаться персональные данные, ссылки для сброса паролей, названия внутренних документов, административные пути и другие важные детали, которые могут быть использованы в целевых атаках.

Пользователям советуют пересмотреть список установленных расширений и удалить те, которыми они не пользуются или которые им незнакомы. Также стоит обращать внимание на разрешение «Читать и изменять данные на всех посещаемых сайтах» — именно оно открывает путь к перехвату URL.



