














Opera решила ударить по одной из самых неприятных схем последних лет — атакам через буфер обмена. В браузере появилась новая функция Paste Protect, которая должна защищать пользователей от подмены скопированных данных и вредоносных команд, которые жертву заставляют вставить в терминал своими руками.
Функция включена по умолчанию и работает прямо на уровне браузера, а не ждет, пока антивирус или операционная система заметят что-то подозрительное.
Paste Protect объединяет два механизма. Первый — уже знакомая защита от перехвата, когда вредонос меняет содержимое буфера обмена. Классика жанра: пользователь копирует криптокошелек или банковский IBAN, а в буфере внезапно оказывается адрес злоумышленника. Opera должна распознать такую подмену и предупредить пользователя.
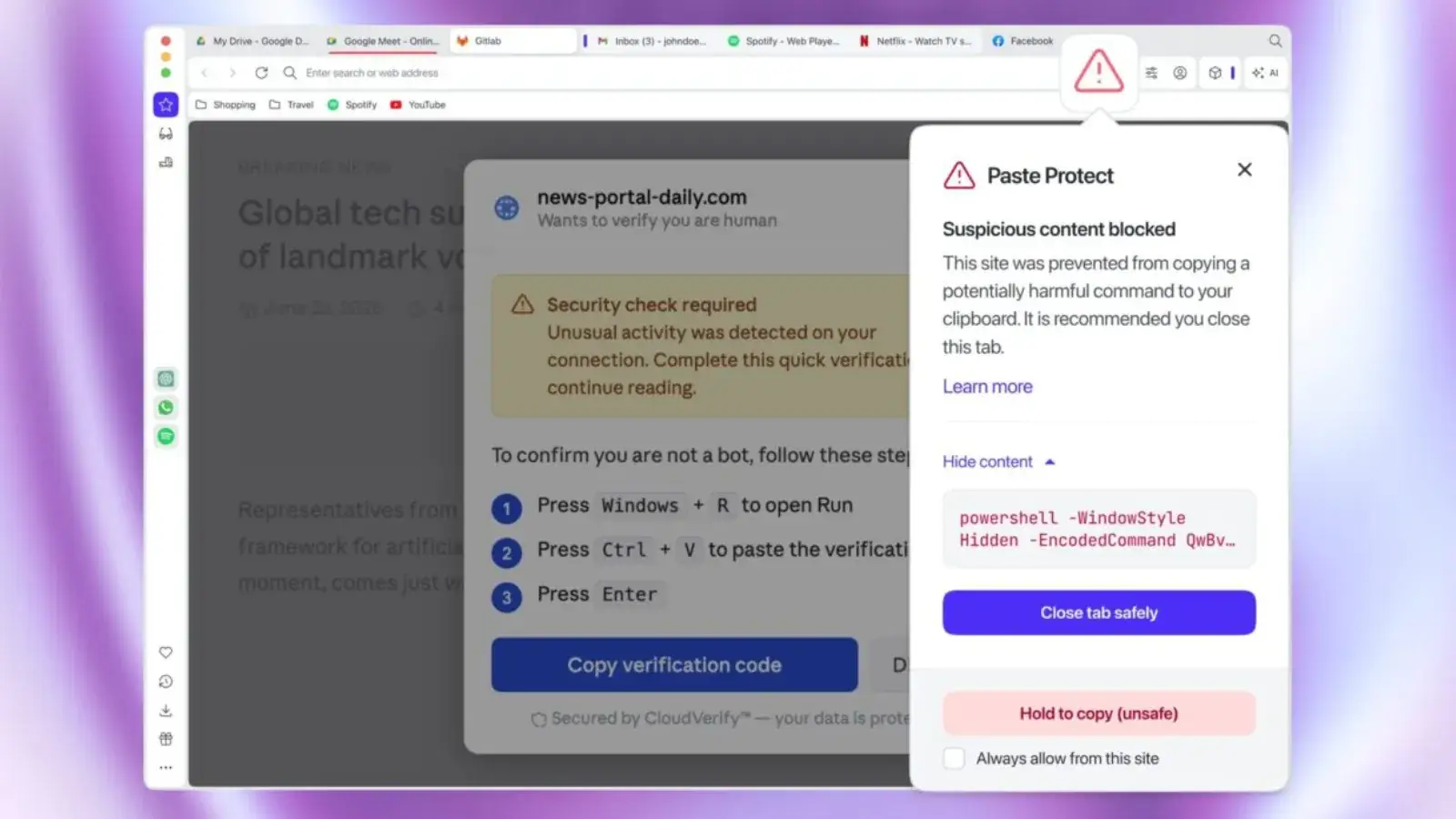
Второй механизм — новая защита от инъекции. Он нацелен на атаки в стиле ClickFix, где пользователя обманывают фейковыми CAPTCHA, ошибками браузера или проблемами с воспроизведением видео. Дальше всё просто: сайт предлагает скопировать команду для исправления проблемы и вставить её в терминал или PowerShell. После этого человек фактически сам запускает вредоносную нагрузку.
Opera теперь анализирует содержимое буфера обмена в реальном времени на Windows, macOS и Linux. Если браузер видит признаки шелл-скрипта, PowerShell-команды, закодированной нагрузки или другого подозрительного содержимого, копирование блокируется, а пользователь получает предупреждение. В уведомлении показывается короткий фрагмент заблокированного текста — до 120 символов.
Для продвинутых пользователей оставили обходные варианты. Например, функцию Hold to Copy, где блокировку можно снять после задержки, а также список доверенных сайтов. Это пригодится разработчикам, которые регулярно копируют команды с GitHub или из документации.
В Opera подчёркивают, что Paste Protect не отменяет здравый смысл. Если сайт просит вставить непонятную команду в терминал, это не починка браузера, а почти наверняка ловушка.



