







 Почтовый сервис "
Почтовый сервис "






Исследователи из Flare.io рассказали о новом Linux-бэкдоре PamDOORa, который продают на русскоязычном киберпреступном форуме Rehub. Автор под ником darkworm сначала просил за инструмент 1600 долларов, но позже снизил цену до 900 долларов.
PamDOORa — это PAM-бэкдор, то есть вредоносный модуль для системы аутентификации Linux. PAM используется в Unix- и Linux-системах для подключения разных механизмов входа: паролей, ключей, биометрии и других вариантов проверки пользователя.
Проблема в том, что PAM-модули обычно работают с высокими привилегиями. Если злоумышленник уже получил root-доступ и установил вредоносный модуль, он может закрепиться в системе надолго.
PamDOORa предназначен именно для постэксплуатации. Сначала атакующему нужно попасть на сервер другим способом, а затем он устанавливает модуль, чтобы сохранить доступ. После этого можно входить по SSH с помощью специального пароля и заданной комбинации TCP-порта.
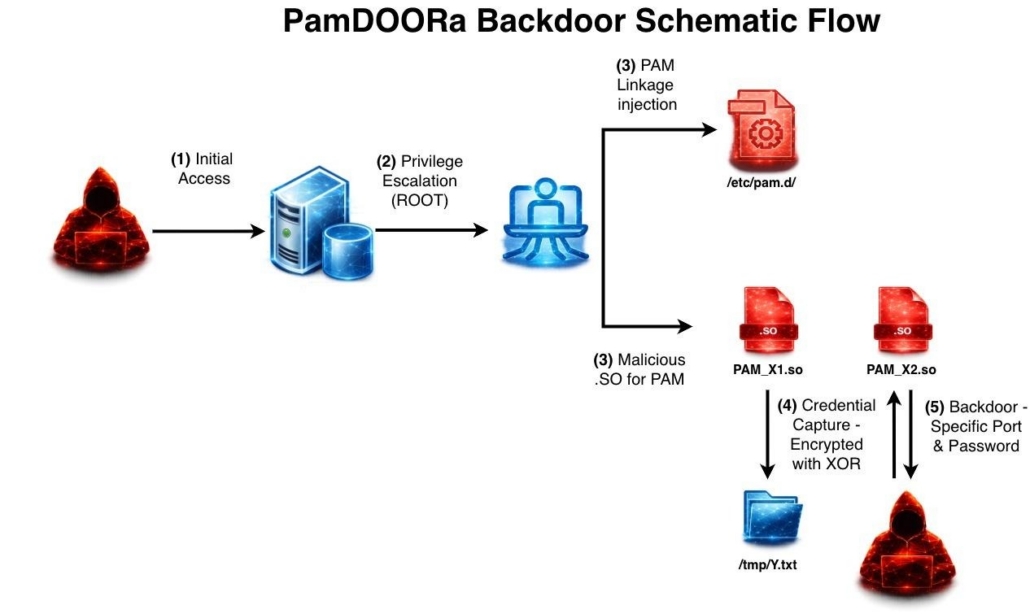
Но этим функциональность не ограничивается. Бэкдор также может перехватывать учётные данные легитимных пользователей, которые проходят аутентификацию через заражённую систему. Иными словами, каждый нормальный вход на сервер может превращаться в источник новых логинов и паролей для атакующего.
Отдельно исследователи отмечают возможности антианализа PamDOORa. Инструмент умеет вмешиваться в журналы аутентификации и удалять следы вредоносной активности, чтобы администратору было сложнее заметить подозрительные входы.
Пока нет подтверждений, что PamDOORa уже применялся в реальных атаках. Но сам факт продажи такого инструмента показывает, что Linux-серверы всё чаще становятся целью не только через уязвимости, но и через механизмы долгосрочного скрытого доступа.
По оценке Flare.io, PamDOORa выглядит более зрелым инструментом, чем обычные публичные бэкдоры для PAM. В нём собраны перехват учётных данных, скрытый SSH-доступ, зачистка логов, антиотладка и сетевые триггеры.



